Στείλτε την καλή δουλειά σας στη βάση γνώσεων είναι απλή. Χρησιμοποιήστε την παρακάτω φόρμα
Φοιτητές, μεταπτυχιακοί φοιτητές, νέοι επιστήμονες που χρησιμοποιούν τη βάση γνώσεων στις σπουδές και την εργασία τους θα σας είναι πολύ ευγνώμονες.
Δημοσιεύτηκε στις http://www.allbest.ru/
Εργασία μαθήματος
πειθαρχία: Βάσεις δεδομένων
Θέμα: ΤεχνολογίαOLAP
Ολοκληρώθηκε το:
Τσιζίκοφ Αλεξάντερ Αλεξάντροβιτς
Εισαγωγή
1. Ταξινόμηση προϊόντων OLAP
2. Πελάτης OLAP - Διακομιστής OLAP: πλεονεκτήματα και μειονεκτήματα
3. Σύστημα πυρήνα OLAP
3.1 Αρχές σχεδιασμού
συμπέρασμα
Κατάλογος πηγών που χρησιμοποιήθηκαν
Εφαρμογές
ΣΕδιεξαγωγής
Είναι δύσκολο να βρεις ένα άτομο στον κόσμο των υπολογιστών που, τουλάχιστον σε διαισθητικό επίπεδο, να μην κατανοεί τι είναι οι βάσεις δεδομένων και γιατί χρειάζονται. Σε αντίθεση με τα παραδοσιακά σχεσιακά DBMS, η έννοια του OLAP δεν είναι τόσο ευρέως γνωστή, αν και σχεδόν όλοι πιθανότατα έχουν ακούσει τον μυστηριώδη όρο «OLAP cubes». Τι είναι η OnLine αναλυτική επεξεργασία;
Το OLAP δεν είναι ξεχωριστό προϊόν λογισμικού, ούτε γλώσσα προγραμματισμού, ούτε καν μια συγκεκριμένη τεχνολογία. Αν προσπαθήσουμε να καλύψουμε το OLAP σε όλες τις εκφάνσεις του, τότε είναι ένα σύνολο εννοιών, αρχών και απαιτήσεων που διέπουν τα προϊόντα λογισμικού που διευκολύνουν την πρόσβαση των αναλυτών στα δεδομένα. Αν και κανείς δεν θα διαφωνούσε με έναν τέτοιο ορισμό, είναι αμφίβολο ότι θα έφερνε τους μη ειδικούς ένα γιώτα πιο κοντά στην κατανόηση του θέματος. Επομένως, στην προσπάθειά σας να κατανοήσετε το OLAP, είναι καλύτερο να ακολουθήσετε έναν διαφορετικό δρόμο. Αρχικά, πρέπει να μάθουμε γιατί οι αναλυτές πρέπει να διευκολύνουν με κάποιο τρόπο συγκεκριμένα την πρόσβαση στα δεδομένα.
Γεγονός είναι ότι οι αναλυτές είναι ειδικοί καταναλωτές εταιρικών πληροφοριών. Το καθήκον του αναλυτή είναι να βρει μοτίβα σε μεγάλες ποσότητες δεδομένων. Επομένως, ο αναλυτής δεν θα δώσει προσοχή σε ένα μόνο γεγονός· χρειάζεται πληροφορίες για εκατοντάδες και χιλιάδες γεγονότα. Παρεμπιπτόντως, ένα από τα σημαντικά σημεία που οδήγησαν στην εμφάνιση του OLAP είναι η παραγωγικότητα και η αποτελεσματικότητα. Ας φανταστούμε τι συμβαίνει όταν ένας αναλυτής χρειάζεται να λάβει πληροφορίες, αλλά δεν υπάρχουν εργαλεία OLAP στην επιχείρηση. Ο αναλυτής ανεξάρτητα (κάτι που είναι απίθανο) ή με τη βοήθεια προγραμματιστή κάνει το κατάλληλο ερώτημα SQL και λαμβάνει τα δεδομένα που ενδιαφέρουν με τη μορφή αναφοράς ή τα εξάγει σε ένα υπολογιστικό φύλλο. Σε αυτή την περίπτωση προκύπτουν πάρα πολλά προβλήματα. Πρώτον, ο αναλυτής αναγκάζεται να κάνει κάτι διαφορετικό από τη δουλειά του (προγραμματισμός SQL) ή να περιμένει τους προγραμματιστές να ολοκληρώσουν την εργασία για αυτόν - όλα αυτά επηρεάζουν αρνητικά την παραγωγικότητα της εργασίας, ο ρυθμός καρδιακής προσβολής και εγκεφαλικού αυξάνεται κ.λπ. Δεύτερον, μια ενιαία αναφορά ή πίνακας, κατά κανόνα, δεν σώζει τους γίγαντες της σκέψης και τους πατέρες της ρωσικής ανάλυσης - και η όλη διαδικασία θα πρέπει να επαναλαμβάνεται ξανά και ξανά. Τρίτον, όπως έχουμε ήδη ανακαλύψει, οι αναλυτές δεν ρωτούν για μικροπράγματα - χρειάζονται τα πάντα ταυτόχρονα. Αυτό σημαίνει (αν και η τεχνολογία προχωρά με άλματα) ότι ο εταιρικός σχεσιακός διακομιστής DBMS στον οποίο έχει πρόσβαση ο αναλυτής μπορεί να σκεφτεί βαθιά και για μεγάλο χρονικό διάστημα, αποκλείοντας άλλες συναλλαγές.
Η ιδέα του OLAP εμφανίστηκε ακριβώς για να λύσει τέτοια προβλήματα. Οι κύβοι OLAP είναι ουσιαστικά μετα-αναφορές. Κόβοντας τις μετα-αναφορές (κύβους, δηλαδή) κατά μήκος διαστάσεων, ο αναλυτής λαμβάνει στην πραγματικότητα τις «συνηθισμένες» δισδιάστατες αναφορές που τον ενδιαφέρουν (αυτές δεν είναι απαραίτητα αναφορές με τη συνήθη έννοια του όρου - μιλάμε για δομές δεδομένων με τις ίδιες λειτουργίες). Τα πλεονεκτήματα των κύβων είναι προφανή - τα δεδομένα πρέπει να ζητηθούν από ένα σχεσιακό DBMS μόνο μία φορά - κατά την κατασκευή ενός κύβου. Δεδομένου ότι οι αναλυτές, κατά κανόνα, δεν εργάζονται με πληροφορίες που συμπληρώνονται και αλλάζουν εν κινήσει, ο κύβος που δημιουργείται είναι σχετικός για μεγάλο χρονικό διάστημα. Χάρη σε αυτό, όχι μόνο εξαλείφονται οι διακοπές στη λειτουργία του σχεσιακού διακομιστή DBMS (δεν υπάρχουν ερωτήματα με χιλιάδες και εκατομμύρια γραμμές απάντησης), αλλά η ταχύτητα πρόσβασης στα δεδομένα για τον ίδιο τον αναλυτή αυξάνεται επίσης απότομα. Επιπλέον, όπως έχει ήδη σημειωθεί, η απόδοση βελτιώνεται επίσης με τον υπολογισμό των υποαθροισμάτων των ιεραρχιών και άλλων συγκεντρωτικών τιμών τη στιγμή που κατασκευάζεται ο κύβος.
Φυσικά, πρέπει να πληρώσετε για να αυξήσετε την παραγωγικότητα με αυτόν τον τρόπο. Μερικές φορές λέγεται ότι η δομή δεδομένων απλώς «εκρήγνυται» - ένας κύβος OLAP μπορεί να καταλάβει δεκάδες ή και εκατοντάδες φορές περισσότερο χώρο από τα αρχικά δεδομένα.
Τώρα που καταλαβαίνουμε λίγο πώς λειτουργεί το OLAP και τι εξυπηρετεί, αξίζει ακόμα να επισημοποιήσουμε κάπως τις γνώσεις μας και να δώσουμε κριτήρια OLAP χωρίς ταυτόχρονη μετάφραση στη συνηθισμένη ανθρώπινη γλώσσα. Τα κριτήρια αυτά (12 συνολικά) διατυπώθηκαν το 1993 από τον Ε.Φ. Codd - ο δημιουργός της έννοιας του σχεσιακού DBMS και, ταυτόχρονα, του OLAP. Δεν θα τα εξετάσουμε άμεσα, καθώς αργότερα επαναλήφθηκαν στη λεγόμενη δοκιμή FASMI, η οποία καθορίζει τις απαιτήσεις για τα προϊόντα OLAP. Το FASMI είναι ένα αρκτικόλεξο για το όνομα κάθε στοιχείου δοκιμής:
Γρήγορα γρήγορα).Αυτή η ιδιότητα σημαίνει ότι το σύστημα πρέπει να παρέχει μια απάντηση σε ένα αίτημα χρήστη κατά μέσο όρο σε πέντε δευτερόλεπτα. Ωστόσο, τα περισσότερα αιτήματα διεκπεραιώνονται μέσα σε ένα δευτερόλεπτο και τα πιο σύνθετα αιτήματα θα πρέπει να διεκπεραιώνονται μέσα σε είκοσι δευτερόλεπτα. Πρόσφατες μελέτες έχουν δείξει ότι ο χρήστης αρχίζει να αμφιβάλλει για την επιτυχία ενός αιτήματος, εάν αυτό διαρκέσει περισσότερα από τριάντα δευτερόλεπτα.
Ανάλυση (αναλυτική).Το σύστημα πρέπει να είναι σε θέση να χειρίζεται οποιαδήποτε λογική και στατιστική ανάλυση τυπική των επιχειρηματικών εφαρμογών και να διασφαλίζει ότι τα αποτελέσματα αποθηκεύονται σε μορφή προσβάσιμη στον τελικό χρήστη. Τα εργαλεία ανάλυσης μπορεί να περιλαμβάνουν διαδικασίες ανάλυσης χρονοσειρών, κατανομής κόστους, μετατροπής νομισμάτων, μοντελοποίησης αλλαγών στις οργανωτικές δομές και ορισμένες άλλες.
Κοινή χρήση.Το σύστημα θα πρέπει να παρέχει άφθονες ευκαιρίες για τον περιορισμό της πρόσβασης στα δεδομένα και την ταυτόχρονη λειτουργία πολλών χρηστών.
Πολυδιάστατο (πολυδιάστατο).Το σύστημα πρέπει να παρέχει μια εννοιολογικά πολυδιάστατη άποψη των δεδομένων, συμπεριλαμβανομένης της πλήρους υποστήριξης για πολλαπλές ιεραρχίες.
Πληροφορίες.Η ισχύς των διαφόρων προϊόντων λογισμικού χαρακτηρίζεται από την ποσότητα των δεδομένων εισόδου που υποβάλλονται σε επεξεργασία. Διαφορετικά συστήματα OLAP έχουν διαφορετικές χωρητικότητες: οι προηγμένες λύσεις OLAP μπορούν να χειριστούν τουλάχιστον χίλιες φορές περισσότερα δεδομένα από τα λιγότερο ισχυρά. Όταν επιλέγετε ένα εργαλείο OLAP, πρέπει να λάβετε υπόψη διάφορους παράγοντες, όπως διπλασιασμό δεδομένων, απαιτήσεις μνήμης, χρήση χώρου στο δίσκο, μετρήσεις απόδοσης, ενοποίηση με αποθήκες πληροφοριών κ.λπ.
1. Ταξινόμηση προϊόντων OLAP
Άρα, η ουσία του OLAP είναι ότι οι αρχικές πληροφορίες για ανάλυση παρουσιάζονται με τη μορφή πολυδιάστατου κύβου και είναι δυνατός ο αυθαίρετος χειρισμός του και η λήψη των απαραίτητων ενοτήτων πληροφοριών - αναφορών. Σε αυτήν την περίπτωση, ο τελικός χρήστης βλέπει τον κύβο ως έναν πολυδιάστατο δυναμικό πίνακα που συνοψίζει αυτόματα δεδομένα (γεγονότα) σε διάφορες ενότητες (διαστάσεις) και επιτρέπει τη διαδραστική διαχείριση των υπολογισμών και της φόρμας αναφοράς. Αυτές οι λειτουργίες εκτελούνται από τη μηχανή OLAP (ή τη μηχανή υπολογισμού OLAP).
Σήμερα, πολλά προϊόντα έχουν αναπτυχθεί σε όλο τον κόσμο που εφαρμόζουν τεχνολογίες OLAP. Για να διευκολυνθεί η πλοήγηση μεταξύ τους, χρησιμοποιούνται ταξινομήσεις προϊόντων OLAP: με τη μέθοδο αποθήκευσης δεδομένων για ανάλυση και από τη θέση του μηχανήματος OLAP. Ας ρίξουμε μια πιο προσεκτική ματιά σε κάθε κατηγορία προϊόντων OLAP.
Θα ξεκινήσω με μια ταξινόμηση με βάση τη μέθοδο αποθήκευσης δεδομένων. Επιτρέψτε μου να σας υπενθυμίσω ότι οι πολυδιάστατοι κύβοι κατασκευάζονται με βάση τα δεδομένα πηγής και συγκεντρωτικών δεδομένων. Τόσο τα δεδομένα πηγής όσο και τα συγκεντρωτικά δεδομένα για κύβους μπορούν να αποθηκευτούν τόσο σε σχεσιακές όσο και σε πολυδιάστατες βάσεις δεδομένων. Επομένως, επί του παρόντος χρησιμοποιούνται τρεις μέθοδοι αποθήκευσης δεδομένων: MOLAP (Πολυδιάστατο OLAP), ROLAP (Σχεσιακό OLAP) και HOLAP (Υβριδικό OLAP). Αντίστοιχα, τα προϊόντα OLAP χωρίζονται σε τρεις παρόμοιες κατηγορίες με βάση τη μέθοδο αποθήκευσης δεδομένων:
1. Στην περίπτωση του MOLAP, τα δεδομένα πηγής και συγκεντρωτικών δεδομένων αποθηκεύονται σε μια πολυδιάστατη βάση δεδομένων ή σε έναν πολυδιάστατο τοπικό κύβο.
2.Στα προϊόντα ROLAP, τα δεδομένα προέλευσης αποθηκεύονται σε σχεσιακές βάσεις δεδομένων ή σε επίπεδους τοπικούς πίνακες σε διακομιστή αρχείων. Τα συγκεντρωτικά δεδομένα μπορούν να τοποθετηθούν σε πίνακες υπηρεσιών στην ίδια βάση δεδομένων. Η μετατροπή δεδομένων από μια σχεσιακή βάση δεδομένων σε πολυδιάστατους κύβους πραγματοποιείται κατόπιν αιτήματος ενός εργαλείου OLAP.
3. Όταν χρησιμοποιείται η αρχιτεκτονική HOLAP, τα δεδομένα προέλευσης παραμένουν στη σχεσιακή βάση δεδομένων και τα συγκεντρωτικά στοιχεία τοποθετούνται στην πολυδιάστατη. Ένας κύβος OLAP δημιουργείται κατόπιν αιτήματος ενός εργαλείου OLAP που βασίζεται σε σχεσιακά και πολυδιάστατα δεδομένα.
Η επόμενη ταξινόμηση βασίζεται στη θέση του μηχανήματος OLAP. Με βάση αυτή τη δυνατότητα, τα προϊόντα OLAP χωρίζονται σε διακομιστές OLAP και πελάτες OLAP:
Στα εργαλεία διακομιστή OLAP, οι υπολογισμοί και η αποθήκευση συγκεντρωτικών δεδομένων εκτελούνται από μια ξεχωριστή διαδικασία - τον διακομιστή. Η εφαρμογή πελάτη λαμβάνει μόνο τα αποτελέσματα των ερωτημάτων σε πολυδιάστατους κύβους που είναι αποθηκευμένοι στο διακομιστή. Ορισμένοι διακομιστές OLAP υποστηρίζουν αποθήκευση δεδομένων μόνο σε σχεσιακές βάσεις δεδομένων, κάποιοι μόνο σε πολυδιάστατες. Πολλοί σύγχρονοι διακομιστές OLAP υποστηρίζουν και τις τρεις μεθόδους αποθήκευσης δεδομένων: MOLAP, ROLAP και HOLAP.
Ο πελάτης OLAP έχει σχεδιαστεί διαφορετικά. Η κατασκευή ενός πολυδιάστατου κύβου και οι υπολογισμοί OLAP εκτελούνται στη μνήμη του υπολογιστή-πελάτη. Οι πελάτες OLAP χωρίζονται επίσης σε ROLAP και MOLAP. Και μερικά μπορεί να υποστηρίζουν και τις δύο επιλογές πρόσβασης δεδομένων.
Κάθε μία από αυτές τις προσεγγίσεις έχει τα δικά της πλεονεκτήματα και μειονεκτήματα. Σε αντίθεση με τη δημοφιλή πεποίθηση για τα πλεονεκτήματα των εργαλείων διακομιστή έναντι των εργαλείων πελάτη, σε ορισμένες περιπτώσεις, η χρήση ενός πελάτη OLAP για χρήστες μπορεί να είναι πιο αποτελεσματική και κερδοφόρα από τη χρήση ενός διακομιστή OLAP.
2. Πελάτης OLAP - Διακομιστής OLAP: πλεονεκτήματα και μειονεκτήματα
Κατά την κατασκευή ενός πληροφοριακού συστήματος, η λειτουργικότητα OLAP μπορεί να υλοποιηθεί χρησιμοποιώντας εργαλεία OLAP διακομιστή και πελάτη. Στην πράξη, η επιλογή είναι μια αντιστάθμιση μεταξύ απόδοσης και κόστους λογισμικού.
Ο όγκος των δεδομένων καθορίζεται από το συνδυασμό των ακόλουθων χαρακτηριστικών: αριθμός εγγραφών, αριθμός διαστάσεων, αριθμός στοιχείων διάστασης, μήκος διαστάσεων και αριθμός γεγονότων. Είναι γνωστό ότι ένας διακομιστής OLAP μπορεί να επεξεργαστεί μεγαλύτερο όγκο δεδομένων από έναν πελάτη OLAP με ίση ισχύ υπολογιστή. Αυτό συμβαίνει επειδή ο διακομιστής OLAP αποθηκεύει μια πολυδιάστατη βάση δεδομένων που περιέχει προυπολογισμένους κύβους σε σκληρούς δίσκους.
Κατά την εκτέλεση λειτουργιών OLAP, τα προγράμματα-πελάτες εκτελούν ερωτήματα σε αυτό σε γλώσσα τύπου SQL, λαμβάνοντας όχι ολόκληρο τον κύβο, αλλά τα εμφανιζόμενα τμήματα του. Ο πελάτης OLAP πρέπει να έχει ολόκληρο τον κύβο στη μνήμη RAM τη στιγμή της λειτουργίας. Στην περίπτωση μιας αρχιτεκτονικής ROLAP, είναι απαραίτητο πρώτα να φορτωθεί στη μνήμη ολόκληρος ο πίνακας δεδομένων που χρησιμοποιείται για τον υπολογισμό του κύβου. Επιπλέον, καθώς αυξάνεται ο αριθμός των διαστάσεων, γεγονότων ή μελών διάστασης, ο αριθμός των αδρανών αυξάνεται εκθετικά. Έτσι, η ποσότητα των δεδομένων που επεξεργάζεται ο πελάτης OLAP εξαρτάται άμεσα από την ποσότητα μνήμης RAM στον υπολογιστή του χρήστη.
Ωστόσο, σημειώστε ότι οι περισσότεροι πελάτες OLAP παρέχουν κατανεμημένους υπολογιστές. Επομένως, ο αριθμός των επεξεργασμένων εγγραφών, που περιορίζει την εργασία του εργαλείου OLAP πελάτη, δεν νοείται ως ο όγκος των πρωτογενών δεδομένων στην εταιρική βάση δεδομένων, αλλά ως το μέγεθος του συγκεντρωτικού δείγματος από αυτήν. Ο πελάτης OLAP δημιουργεί ένα αίτημα στο DBMS, το οποίο περιγράφει τις συνθήκες φιλτραρίσματος και τον αλγόριθμο για την προκαταρκτική ομαδοποίηση των πρωτογενών δεδομένων. Ο διακομιστής βρίσκει, ομαδοποιεί εγγραφές και επιστρέφει μια συμπαγή επιλογή για περαιτέρω υπολογισμούς OLAP. Το μέγεθος αυτού του δείγματος μπορεί να είναι δεκάδες ή εκατοντάδες φορές μικρότερο από τον όγκο των πρωτογενών, μη συγκεντρωτικών εγγραφών. Κατά συνέπεια, η ανάγκη για έναν τέτοιο πελάτη OLAP σε πόρους υπολογιστή μειώνεται σημαντικά.
Επιπλέον, ο αριθμός των διαστάσεων υπόκειται σε περιορισμούς στην ανθρώπινη αντίληψη. Είναι γνωστό ότι ο μέσος άνθρωπος μπορεί ταυτόχρονα να λειτουργεί με 3-4, το πολύ 8 διαστάσεις. Με μεγαλύτερο αριθμό διαστάσεων σε έναν δυναμικό πίνακα, η αντίληψη των πληροφοριών γίνεται σημαντικά πιο δύσκολη. Αυτός ο παράγοντας θα πρέπει να λαμβάνεται υπόψη κατά τον προκαταρκτικό υπολογισμό της μνήμης RAM που μπορεί να απαιτείται από τον πελάτη OLAP.
Το μήκος των διαστάσεων επηρεάζει επίσης το μέγεθος του χώρου διευθύνσεων του κινητήρα OLAP κατά τον υπολογισμό ενός κύβου OLAP. Όσο μεγαλύτερες είναι οι διαστάσεις, τόσο περισσότεροι πόροι απαιτούνται για την προεπιλογή ενός πολυδιάστατου πίνακα και το αντίστροφο. Μόνο οι σύντομες μετρήσεις στα δεδομένα προέλευσης είναι ένα άλλο επιχείρημα υπέρ του προγράμματος-πελάτη OLAP.
Αυτό το χαρακτηριστικό καθορίζεται από τους δύο παράγοντες που συζητήθηκαν παραπάνω: τον όγκο των δεδομένων που υποβάλλονται σε επεξεργασία και την ισχύ των υπολογιστών. Καθώς, για παράδειγμα, ο αριθμός των διαστάσεων αυξάνεται, η απόδοση όλων των εργαλείων OLAP μειώνεται λόγω σημαντικής αύξησης του αριθμού των αδρανών, αλλά ο ρυθμός μείωσης είναι διαφορετικός. Ας δείξουμε αυτή την εξάρτηση από ένα γράφημα.
Σχήμα 1. Εξάρτηση της απόδοσης των εργαλείων OLAP πελάτη και διακομιστή από την αύξηση του όγκου δεδομένων
Τα χαρακτηριστικά ταχύτητας ενός διακομιστή OLAP είναι λιγότερο ευαίσθητα στην ανάπτυξη δεδομένων. Αυτό εξηγείται από διαφορετικές τεχνολογίες για την επεξεργασία των αιτημάτων των χρηστών από τον διακομιστή OLAP και τον πελάτη OLAP. Για παράδειγμα, κατά τη διάρκεια μιας λεπτομερούς λειτουργίας, ο διακομιστής OLAP έχει πρόσβαση στα αποθηκευμένα δεδομένα και «τραβάει» τα δεδομένα από αυτήν την «υποκατάστημα». Ο πελάτης OLAP υπολογίζει ολόκληρο το σύνολο των συγκεντρωτικών στοιχείων τη στιγμή της φόρτωσης. Ωστόσο, μέχρι ένα ορισμένο ποσό δεδομένων, η απόδοση των εργαλείων διακομιστή και πελάτη είναι συγκρίσιμη. Για πελάτες OLAP που υποστηρίζουν κατανεμημένους υπολογιστές, το εύρος της συγκρισιμότητας απόδοσης μπορεί να επεκταθεί σε όγκους δεδομένων που καλύπτουν τις ανάγκες ανάλυσης OLAP ενός τεράστιου αριθμού χρηστών. Αυτό επιβεβαιώνεται από τα αποτελέσματα των εσωτερικών δοκιμών του διακομιστή MS OLAP και του πελάτη OLAP "Kontur Standard". Η δοκιμή πραγματοποιήθηκε σε υπολογιστή IBM Pentium Celeron 400 MHz, 256 Mb για δείγμα 1 εκατομμυρίου μοναδικών (δηλαδή συγκεντρωτικών) εγγραφών με 7 διαστάσεις που περιείχαν από 10 έως 70 μέλη. Ο χρόνος φόρτωσης του κύβου και στις δύο περιπτώσεις δεν ξεπερνά το 1 δευτερόλεπτο και διάφορες λειτουργίες OLAP (τρύπημα πάνω, διάτρηση, μετακίνηση, φιλτράρισμα κ.λπ.) ολοκληρώνονται σε εκατοστά του δευτερολέπτου.
Όταν το μέγεθος του δείγματος υπερβαίνει την ποσότητα της μνήμης RAM, αρχίζει η εναλλαγή με το δίσκο και η απόδοση του προγράμματος-πελάτη OLAP μειώνεται απότομα. Μόνο από αυτή τη στιγμή μπορούμε να μιλήσουμε για το πλεονέκτημα του διακομιστή OLAP.
Θα πρέπει να θυμόμαστε ότι το "σημείο θραύσης" καθορίζει το όριο μιας απότομης αύξησης του κόστους μιας λύσης OLAP. Για τις εργασίες κάθε συγκεκριμένου χρήστη, αυτό το σημείο προσδιορίζεται εύκολα από δοκιμές απόδοσης του προγράμματος-πελάτη OLAP. Τέτοιες δοκιμές μπορούν να ληφθούν από την εταιρεία ανάπτυξης.
Επιπλέον, το κόστος μιας λύσης OLAP διακομιστή αυξάνεται καθώς αυξάνεται ο αριθμός των χρηστών. Το γεγονός είναι ότι ο διακομιστής OLAP εκτελεί υπολογισμούς για όλους τους χρήστες σε έναν υπολογιστή. Αντίστοιχα, όσο μεγαλύτερος είναι ο αριθμός των χρηστών, τόσο περισσότερη μνήμη RAM και επεξεργαστική ισχύς. Έτσι, εάν οι όγκοι των δεδομένων που υποβάλλονται σε επεξεργασία βρίσκονται στην περιοχή της συγκρίσιμης απόδοσης συστημάτων διακομιστή και πελατών, τότε, αν είναι ίσα τα άλλα πράγματα, η χρήση ενός πελάτη OLAP θα είναι πιο κερδοφόρα.
Η χρήση ενός διακομιστή OLAP στην «κλασική» ιδεολογία περιλαμβάνει τη μεταφόρτωση σχεσιακών δεδομένων DBMS σε μια πολυδιάστατη βάση δεδομένων. Η μεταφόρτωση πραγματοποιείται σε μια συγκεκριμένη περίοδο, επομένως τα δεδομένα διακομιστή OLAP δεν αντικατοπτρίζουν την τρέχουσα κατάσταση. Μόνο οι διακομιστές OLAP που υποστηρίζουν τη λειτουργία ROLAP δεν έχουν αυτό το μειονέκτημα.
Ομοίως, ένας αριθμός πελατών OLAP σάς επιτρέπει να εφαρμόσετε αρχιτεκτονικές ROLAP και Desktop με άμεση πρόσβαση στη βάση δεδομένων. Αυτό διασφαλίζει την ηλεκτρονική ανάλυση των δεδομένων πηγής.
Ο διακομιστής OLAP θέτει ελάχιστες απαιτήσεις για την ισχύ των τερματικών πελατών. Αντικειμενικά, οι απαιτήσεις ενός πελάτη OLAP είναι υψηλότερες, επειδή... εκτελεί υπολογισμούς στη μνήμη RAM του υπολογιστή του χρήστη. Η κατάσταση του στόλου υλικού ενός συγκεκριμένου οργανισμού είναι ο πιο σημαντικός δείκτης που πρέπει να λαμβάνεται υπόψη κατά την επιλογή ενός εργαλείου OLAP. Αλλά υπάρχουν και «υπέρ» και «μειονεκτήματα» εδώ. Ένας διακομιστής OLAP δεν χρησιμοποιεί την τεράστια υπολογιστική ισχύ των σύγχρονων προσωπικών υπολογιστών. Εάν ένας οργανισμός διαθέτει ήδη ένα στόλο σύγχρονων υπολογιστών, είναι αναποτελεσματικό να τους χρησιμοποιεί μόνο ως τερματικά οθόνης και ταυτόχρονα να επιβαρύνει τον κεντρικό διακομιστή.
Εάν η ισχύς των υπολογιστών των χρηστών "απομένει πολύ", ο πελάτης OLAP θα λειτουργεί αργά ή δεν θα μπορεί να λειτουργήσει καθόλου. Η αγορά ενός ισχυρού διακομιστή μπορεί να είναι φθηνότερη από την αναβάθμιση όλων των υπολογιστών σας.
Εδώ είναι χρήσιμο να ληφθούν υπόψη οι τάσεις στην ανάπτυξη υλικού. Δεδομένου ότι ο όγκος των δεδομένων για ανάλυση είναι πρακτικά σταθερός, μια σταθερή αύξηση της ισχύος του υπολογιστή θα οδηγήσει σε επέκταση των δυνατοτήτων των πελατών OLAP και στη μετατόπιση των διακομιστών OLAP στο τμήμα πολύ μεγάλων βάσεων δεδομένων.
Όταν χρησιμοποιείτε έναν διακομιστή OLAP μέσω του δικτύου, μόνο τα προς εμφάνιση δεδομένα μεταφέρονται στον υπολογιστή του πελάτη, ενώ ο πελάτης OLAP λαμβάνει ολόκληρο τον όγκο των πρωτογενών δεδομένων.
Επομένως, όπου χρησιμοποιείται πελάτης OLAP, η κίνηση δικτύου θα είναι μεγαλύτερη.
Όμως, όταν χρησιμοποιείτε έναν διακομιστή OLAP, οι λειτουργίες του χρήστη, για παράδειγμα, η λεπτομέρεια, δημιουργούν νέα ερωτήματα στην πολυδιάστατη βάση δεδομένων και, επομένως, νέα μεταφορά δεδομένων. Η εκτέλεση των λειτουργιών OLAP από έναν πελάτη OLAP εκτελείται στη μνήμη RAM και, κατά συνέπεια, δεν προκαλεί νέες ροές δεδομένων στο δίκτυο.
Θα πρέπει επίσης να σημειωθεί ότι το σύγχρονο υλικό δικτύου παρέχει υψηλά επίπεδα απόδοσης.
Επομένως, στη συντριπτική πλειονότητα των περιπτώσεων, η ανάλυση μιας βάσης δεδομένων «μεσαίου» μεγέθους χρησιμοποιώντας έναν πελάτη OLAP δεν θα επιβραδύνει την εργασία του χρήστη.
Το κόστος ενός διακομιστή OLAP είναι αρκετά υψηλό. Αυτό θα πρέπει επίσης να περιλαμβάνει το κόστος ενός αποκλειστικού υπολογιστή και το τρέχον κόστος διαχείρισης μιας πολυδιάστατης βάσης δεδομένων. Επιπλέον, η υλοποίηση και η συντήρηση ενός διακομιστή OLAP απαιτεί προσωπικό αρκετά υψηλού επιπέδου.
Το κόστος ενός πελάτη OLAP είναι μια τάξη μεγέθους χαμηλότερο από το κόστος ενός διακομιστή OLAP. Δεν απαιτείται διαχείριση ή πρόσθετος τεχνικός εξοπλισμός για τον διακομιστή. Δεν υπάρχουν υψηλές απαιτήσεις για προσόντα προσωπικού κατά την εφαρμογή ενός πελάτη OLAP. Ένας πελάτης OLAP μπορεί να υλοποιηθεί πολύ πιο γρήγορα από έναν διακομιστή OLAP.
Η ανάπτυξη αναλυτικών εφαρμογών με χρήση εργαλείων πελάτη OLAP είναι μια γρήγορη διαδικασία και δεν απαιτεί ειδική εκπαίδευση. Ένας χρήστης που γνωρίζει τη φυσική υλοποίηση της βάσης δεδομένων μπορεί να αναπτύξει μια αναλυτική εφαρμογή ανεξάρτητα, χωρίς τη συμμετοχή ειδικού πληροφορικής. Όταν χρησιμοποιείτε έναν διακομιστή OLAP, πρέπει να μάθετε 2 διαφορετικά συστήματα, μερικές φορές από διαφορετικούς προμηθευτές - να δημιουργήσετε κύβους στον διακομιστή και να αναπτύξετε μια εφαρμογή πελάτη. Ο πελάτης OLAP παρέχει μια ενιαία οπτική διεπαφή για την περιγραφή κύβων και τη ρύθμιση διεπαφών χρήστη για αυτούς.
Ας προχωρήσουμε στη διαδικασία δημιουργίας μιας εφαρμογής OLAP χρησιμοποιώντας το εργαλείο πελάτη.
Διάγραμμα 2. Δημιουργία εφαρμογής OLAP με χρήση εργαλείου πελάτη ROLAP
Η αρχή λειτουργίας των πελατών ROLAP είναι μια προκαταρκτική περιγραφή του σημασιολογικού επιπέδου, πίσω από το οποίο κρύβεται η φυσική δομή των δεδομένων προέλευσης. Σε αυτήν την περίπτωση, οι πηγές δεδομένων μπορεί να είναι: τοπικοί πίνακες, RDBMS. Η λίστα των υποστηριζόμενων πηγών δεδομένων καθορίζεται από το συγκεκριμένο προϊόν λογισμικού. Μετά από αυτό, ο χρήστης μπορεί να χειριστεί ανεξάρτητα αντικείμενα που κατανοεί από την άποψη της θεματικής περιοχής για να δημιουργήσει κύβους και αναλυτικές διεπαφές.
Η αρχή λειτουργίας του πελάτη διακομιστή OLAP είναι διαφορετική. Σε έναν διακομιστή OLAP, κατά τη δημιουργία κύβων, ο χρήστης χειρίζεται τις φυσικές περιγραφές της βάσης δεδομένων.
Ταυτόχρονα, δημιουργούνται προσαρμοσμένες περιγραφές στον ίδιο τον κύβο. Ο πελάτης διακομιστή OLAP έχει ρυθμιστεί μόνο για τον κύβο.
Ας εξηγήσουμε την αρχή λειτουργίας του πελάτη ROLAP χρησιμοποιώντας το παράδειγμα δημιουργίας μιας δυναμικής αναφοράς πωλήσεων (βλ. Διάγραμμα 2). Αφήστε τα αρχικά δεδομένα για ανάλυση να αποθηκευτούν σε δύο πίνακες: Πωλήσεις και Συμφωνία.
Κατά τη δημιουργία ενός σημασιολογικού επιπέδου, οι πηγές δεδομένων - οι πίνακες πωλήσεων και συμφωνιών - περιγράφονται με όρους που μπορεί να κατανοήσει ο τελικός χρήστης και να μετατραπεί σε "Προϊόντα" και "Συμφωνίες". Το πεδίο "ID" από τον πίνακα "Προϊόντα" μετονομάζεται σε "Κωδικός" και το "Όνομα" σε "Προϊόν" κ.λπ.
Στη συνέχεια δημιουργείται το αντικείμενο της επιχείρησης πωλήσεων. Ένα επιχειρηματικό αντικείμενο είναι ένα επίπεδο τραπέζι με βάση το οποίο σχηματίζεται ένας πολυδιάστατος κύβος. Κατά τη δημιουργία ενός επιχειρηματικού αντικειμένου, οι πίνακες "Προϊόντα" και "Συναλλαγές" συγχωνεύονται από το πεδίο "Κωδικός" του προϊόντος. Δεδομένου ότι όλα τα πεδία πίνακα δεν απαιτούνται για εμφάνιση στην αναφορά, το επιχειρηματικό αντικείμενο χρησιμοποιεί μόνο τα πεδία "Στοιχείο", "Ημερομηνία" και "Ποσό".
Στη συνέχεια, δημιουργείται μια αναφορά OLAP με βάση το επιχειρηματικό αντικείμενο. Ο χρήστης επιλέγει ένα επαγγελματικό αντικείμενο και σύρει τα χαρακτηριστικά του στις περιοχές στηλών ή σειρών του πίνακα αναφοράς. Στο παράδειγμά μας, με βάση το επιχειρηματικό αντικείμενο "Πωλήσεις", δημιουργήθηκε μια αναφορά για τις πωλήσεις προϊόντων ανά μήνα.
Όταν εργάζεστε με μια διαδραστική αναφορά, ο χρήστης μπορεί να ορίσει συνθήκες φιλτραρίσματος και ομαδοποίησης με τις ίδιες απλές κινήσεις του ποντικιού. Σε αυτό το σημείο, ο πελάτης ROLAP έχει πρόσβαση στα δεδομένα στη μνήμη cache. Ο πελάτης διακομιστή OLAP δημιουργεί ένα νέο ερώτημα στην πολυδιάστατη βάση δεδομένων. Για παράδειγμα, εφαρμόζοντας ένα φίλτρο ανά προϊόν σε μια αναφορά πωλήσεων, μπορείτε να λάβετε μια αναφορά για τις πωλήσεις προϊόντων που μας ενδιαφέρουν.
Όλες οι ρυθμίσεις της εφαρμογής OLAP μπορούν να αποθηκευτούν σε έναν αποκλειστικό χώρο αποθήκευσης μεταδεδομένων, στην εφαρμογή ή σε έναν χώρο αποθήκευσης συστήματος πολυδιάστατης βάσης δεδομένων. Η εφαρμογή εξαρτάται από το συγκεκριμένο προϊόν λογισμικού.
Επομένως, σε ποιες περιπτώσεις η χρήση ενός πελάτη OLAP μπορεί να είναι πιο αποτελεσματική και κερδοφόρα για τους χρήστες από τη χρήση ενός διακομιστή OLAP;
Η οικονομική σκοπιμότητα της χρήσης διακομιστή OLAP προκύπτει όταν ο όγκος των δεδομένων είναι πολύ μεγάλος και συντριπτικός για τον πελάτη OLAP, διαφορετικά η χρήση του τελευταίου είναι πιο δικαιολογημένη. Σε αυτήν την περίπτωση, ο πελάτης OLAP συνδυάζει χαρακτηριστικά υψηλής απόδοσης και χαμηλό κόστος.
Οι ισχυροί υπολογιστές για τους αναλυτές είναι ένα άλλο επιχείρημα υπέρ των πελατών OLAP. Όταν χρησιμοποιείτε διακομιστή OLAP, αυτές οι δυνατότητες δεν χρησιμοποιούνται. Μεταξύ των πλεονεκτημάτων των πελατών OLAP είναι τα ακόλουθα:
Το κόστος υλοποίησης και συντήρησης ενός πελάτη OLAP είναι σημαντικά χαμηλότερο από το κόστος ενός διακομιστή OLAP.
Όταν χρησιμοποιείτε έναν πελάτη OLAP με ενσωματωμένο μηχάνημα, τα δεδομένα μεταφέρονται μέσω του δικτύου μία φορά. Κατά την εκτέλεση λειτουργιών OLAP, δεν δημιουργούνται νέες ροές δεδομένων.
Η ρύθμιση των πελατών ROLAP απλοποιείται εξαλείφοντας το ενδιάμεσο βήμα - τη δημιουργία μιας πολυδιάστατης βάσης δεδομένων.
3. Σύστημα πυρήνα OLAP
3.1 Αρχές σχεδιασμού
βασικά δεδομένα πελάτη εφαρμογής
Από όσα αναφέρθηκαν ήδη, είναι σαφές ότι ο μηχανισμός OLAP είναι μία από τις δημοφιλείς μεθόδους ανάλυσης δεδομένων σήμερα. Υπάρχουν δύο κύριες προσεγγίσεις για την επίλυση αυτού του προβλήματος. Το πρώτο από αυτά ονομάζεται Multidimensional OLAP (MOLAP) - υλοποίηση του μηχανισμού χρησιμοποιώντας μια πολυδιάστατη βάση δεδομένων στην πλευρά του διακομιστή και το δεύτερο Relational OLAP (ROLAP) - δημιουργία κύβων εν κινήσει με βάση ερωτήματα SQL σε ένα σχεσιακό DBMS. Κάθε μία από αυτές τις προσεγγίσεις έχει τα υπέρ και τα κατά της. Η συγκριτική τους ανάλυση ξεφεύγει από το σκοπό αυτής της εργασίας. Εδώ θα περιγραφεί μόνο η βασική υλοποίηση της λειτουργικής μονάδας ROLAP επιφάνειας εργασίας.
Αυτή η εργασία προέκυψε μετά τη χρήση ενός συστήματος ROLAP που δημιουργήθηκε με βάση τα στοιχεία του κύβου απόφασης που περιλαμβάνονται στο Borland Delphi. Δυστυχώς, η χρήση αυτού του συνόλου στοιχείων έδειξε κακή απόδοση σε μεγάλους όγκους δεδομένων. Αυτό το πρόβλημα μπορεί να μετριαστεί προσπαθώντας να αποκόψετε όσο το δυνατόν περισσότερα δεδομένα πριν τα τροφοδοτήσετε σε κύβους. Αλλά αυτό δεν είναι πάντα αρκετό.
Μπορείτε να βρείτε πολλές πληροφορίες για τα συστήματα OLAP στο Διαδίκτυο και στον Τύπο, αλλά σχεδόν πουθενά δεν αναφέρεται πώς λειτουργεί στο εσωτερικό του.
Πρόγραμμα εργασίας:
Το γενικό σχήμα λειτουργίας ενός επιτραπέζιου συστήματος OLAP μπορεί να αναπαρασταθεί ως εξής:
Διάγραμμα 3. Λειτουργία επιτραπέζιου συστήματος OLAP
Ο αλγόριθμος λειτουργίας είναι ο εξής:
1. Λήψη δεδομένων με τη μορφή ενός επίπεδου πίνακα ή το αποτέλεσμα της εκτέλεσης ενός ερωτήματος SQL.
2. Αποθήκευση δεδομένων και μετατροπή τους σε πολυδιάστατο κύβο.
3. Εμφάνιση του κατασκευασμένου κύβου με τη χρήση διασταυρούμενης καρτέλας ή γραφήματος κ.λπ. Γενικά, ένας αυθαίρετος αριθμός προβολών μπορεί να συνδεθεί σε έναν κύβο.
Ας εξετάσουμε πώς μπορεί να διευθετηθεί εσωτερικά ένα τέτοιο σύστημα. Θα ξεκινήσουμε από την πλευρά που φαίνεται και αγγίζεται, δηλαδή από τις οθόνες. Οι οθόνες που χρησιμοποιούνται στα συστήματα OLAP συνήθως διατίθενται σε δύο τύπους - cross-tabs και γραφήματα. Ας δούμε μια διασταύρωση, η οποία είναι ο βασικός και πιο συνηθισμένος τρόπος εμφάνισης ενός κύβου.
Στο παρακάτω σχήμα, οι σειρές και οι στήλες που περιέχουν συγκεντρωτικά αποτελέσματα εμφανίζονται με κίτρινο, τα κελιά που περιέχουν στοιχεία είναι με ανοιχτό γκρι και τα κελιά που περιέχουν δεδομένα διαστάσεων είναι με σκούρο γκρι.
Έτσι, ο πίνακας μπορεί να χωριστεί στα ακόλουθα στοιχεία, με τα οποία θα εργαστούμε στο μέλλον:
Όταν συμπληρώνουμε τον πίνακα με γεγονότα, πρέπει να προχωρήσουμε ως εξής:
Με βάση τα δεδομένα μέτρησης, προσδιορίστε τις συντεταγμένες του στοιχείου που θα προστεθεί στον πίνακα.
Προσδιορίστε τις συντεταγμένες των στηλών και των γραμμών των συνόλων που επηρεάζονται από το προστιθέμενο στοιχείο.
Προσθέστε ένα στοιχείο στον πίνακα και τις αντίστοιχες συνολικές στήλες και γραμμές.
Θα πρέπει να σημειωθεί ότι η μήτρα που θα προκύψει θα είναι πολύ αραιή, γι' αυτό και η οργάνωσή της με τη μορφή δισδιάστατου πίνακα (η επιλογή που βρίσκεται στην επιφάνεια) είναι όχι μόνο παράλογη, αλλά, πιθανότατα, αδύνατη λόγω του μεγάλου διάσταση αυτού του πίνακα, για την αποθήκευση του οποίου δεν υπάρχει Δεν αρκεί η ποσότητα μνήμης RAM. Για παράδειγμα, εάν ο κύβος μας περιέχει πληροφορίες σχετικά με τις πωλήσεις για ένα έτος και εάν έχει μόνο 3 διαστάσεις - Πελάτες (250), Προϊόντα (500) και Ημερομηνία (365), τότε θα λάβουμε έναν πίνακα γεγονότων με τις ακόλουθες διαστάσεις: αριθμός στοιχείων = 250 x 500 x 365 = 45.625.000. Και αυτό παρά το γεγονός ότι μπορεί να υπάρχουν μόνο μερικές χιλιάδες γεμάτα στοιχεία στη μήτρα. Επιπλέον, όσο μεγαλύτερος είναι ο αριθμός των διαστάσεων, τόσο πιο αραιός θα είναι ο πίνακας.
Επομένως, για να εργαστείτε με αυτόν τον πίνακα, πρέπει να χρησιμοποιήσετε ειδικούς μηχανισμούς για εργασία με αραιούς πίνακες. Είναι δυνατές διάφορες επιλογές για την οργάνωση μιας αραιής μήτρας. Περιγράφονται αρκετά καλά στη βιβλιογραφία προγραμματισμού, για παράδειγμα, στον πρώτο τόμο του κλασικού βιβλίου «The Art of Programming» του Donald Knuth.
Ας εξετάσουμε τώρα πώς μπορούμε να προσδιορίσουμε τις συντεταγμένες ενός γεγονότος, γνωρίζοντας τις διαστάσεις που αντιστοιχούν σε αυτό. Για να γίνει αυτό, ας ρίξουμε μια πιο προσεκτική ματιά στη δομή της κεφαλίδας:
Σε αυτήν την περίπτωση, μπορείτε εύκολα να βρείτε έναν τρόπο να προσδιορίσετε τους αριθμούς του αντίστοιχου κελιού και τα σύνολα στα οποία εμπίπτει. Εδώ μπορούν να προταθούν διάφορες προσεγγίσεις. Το ένα είναι να χρησιμοποιήσετε ένα δέντρο για να βρείτε αντίστοιχα κελιά. Αυτό το δέντρο μπορεί να κατασκευαστεί διασχίζοντας την επιλογή. Επιπλέον, ένας αναλυτικός τύπος επανάληψης μπορεί εύκολα να οριστεί για τον υπολογισμό της απαιτούμενης συντεταγμένης.
Τα δεδομένα που είναι αποθηκευμένα στον πίνακα πρέπει να μετασχηματιστούν για να χρησιμοποιηθούν. Έτσι, για να βελτιωθεί η απόδοση κατά την κατασκευή ενός υπερκύβου, είναι επιθυμητό να βρεθούν μοναδικά στοιχεία αποθηκευμένα σε στήλες που έχουν διαστάσεις του κύβου. Επιπλέον, μπορείτε να πραγματοποιήσετε προκαταρκτική συγκέντρωση γεγονότων για εγγραφές που έχουν τις ίδιες τιμές διαστάσεων. Όπως αναφέρθηκε παραπάνω, οι μοναδικές τιμές που είναι διαθέσιμες στα πεδία μέτρησης είναι σημαντικές για εμάς. Στη συνέχεια μπορεί να προταθεί η ακόλουθη δομή για την αποθήκευσή τους:
Σχήμα 4. Δομή για την αποθήκευση μοναδικών τιμών
Χρησιμοποιώντας αυτή τη δομή, μειώνουμε σημαντικά την απαίτηση μνήμης. Κάτι που είναι αρκετά σχετικό, γιατί... Για να αυξήσετε την ταχύτητα λειτουργίας, συνιστάται η αποθήκευση δεδομένων στη μνήμη RAM. Επιπλέον, μπορείτε να αποθηκεύσετε μόνο μια σειρά στοιχείων και να αποθέσετε τις τιμές τους στο δίσκο, καθώς θα τα χρειαστούμε μόνο όταν εμφανίζουμε τη διασταύρωση.
Οι ιδέες που περιγράφονται παραπάνω ήταν η βάση για τη δημιουργία της βιβλιοθήκης στοιχείων CubeBase.
Διάγραμμα 5. Δομή της βιβλιοθήκης στοιχείων CubeBase
Το TСubeSource εκτελεί προσωρινή αποθήκευση και μετατροπή δεδομένων σε εσωτερική μορφή, καθώς και προκαταρκτική συγκέντρωση δεδομένων. Το στοιχείο TCubeEngine εκτελεί υπολογισμούς και λειτουργίες υπερκύβου με αυτό. Στην πραγματικότητα, είναι μια μηχανή OLAP που μετατρέπει ένα επίπεδο τραπέζι σε ένα πολυδιάστατο σύνολο δεδομένων. Το στοιχείο TCubeGrid εμφανίζει τη διασταύρωση και ελέγχει την εμφάνιση του υπερκύβου. Το TСubeChart σάς επιτρέπει να βλέπετε τον υπερκύβο με τη μορφή γραφημάτων και το στοιχείο TСubePivote ελέγχει τη λειτουργία του πυρήνα του κύβου.
Έτσι, εξέτασα την αρχιτεκτονική και την αλληλεπίδραση των στοιχείων που μπορούν να χρησιμοποιηθούν για την κατασκευή ενός μηχανήματος OLAP. Τώρα ας ρίξουμε μια πιο προσεκτική ματιά στην εσωτερική δομή των εξαρτημάτων.
Το πρώτο στάδιο του συστήματος θα είναι η φόρτωση δεδομένων και η μετατροπή τους σε εσωτερική μορφή. Μια λογική ερώτηση θα ήταν: γιατί είναι απαραίτητο, αφού μπορείτε απλά να χρησιμοποιήσετε δεδομένα από έναν επίπεδο πίνακα, προβάλλοντάς τα κατά την κατασκευή μιας φέτας κύβου. Για να απαντήσουμε σε αυτήν την ερώτηση, ας δούμε τη δομή του πίνακα από τη σκοπιά μιας μηχανής OLAP. Για συστήματα OLAP, οι στήλες πίνακα μπορεί να είναι είτε γεγονότα είτε διαστάσεις. Ωστόσο, η λογική για την εργασία με αυτές τις στήλες θα είναι διαφορετική. Σε έναν υπερκύβο, οι διαστάσεις είναι στην πραγματικότητα οι άξονες και οι τιμές διαστάσεων είναι οι συντεταγμένες σε αυτούς τους άξονες. Σε αυτήν την περίπτωση, ο κύβος θα γεμίσει πολύ άνισα - θα υπάρχουν συνδυασμοί συντεταγμένων που δεν θα αντιστοιχούν σε καμία εγγραφή και θα υπάρχουν συνδυασμοί που αντιστοιχούν σε πολλές εγγραφές στον αρχικό πίνακα και η πρώτη κατάσταση είναι πιο συνηθισμένη, δηλαδή , ο κύβος θα είναι παρόμοιος με το σύμπαν - κενός χώρος, σε ορισμένα σημεία που υπάρχουν συστάδες σημείων (γεγονότα). Έτσι, εάν πραγματοποιήσουμε προ-συγκέντρωση δεδομένων κατά την αρχική φόρτωση δεδομένων, δηλαδή συνδυάσουμε εγγραφές που έχουν τις ίδιες τιμές μέτρησης, ενώ υπολογίζουμε προκαταρκτικές συγκεντρωτικές τιμές γεγονότων, τότε στο μέλλον θα πρέπει να εργαστούμε με λιγότερες εγγραφές, γεγονός που θα αυξήσει το ταχύτητα εργασίας και μείωση των απαιτήσεων στην ποσότητα της μνήμης RAM.
Για να δημιουργήσουμε φέτες ενός υπερκύβου, χρειαζόμαστε τις ακόλουθες δυνατότητες - ορισμό συντεταγμένων (στην πραγματικότητα τιμών μέτρησης) για εγγραφές πίνακα, καθώς και καθορισμό εγγραφών που έχουν συγκεκριμένες συντεταγμένες (τιμές μέτρησης). Ας εξετάσουμε πώς μπορούν να πραγματοποιηθούν αυτές οι δυνατότητες. Ο ευκολότερος τρόπος αποθήκευσης ενός υπερκύβου είναι να χρησιμοποιήσετε μια βάση δεδομένων με τη δική του εσωτερική μορφή.
Σχηματικά, οι μετασχηματισμοί μπορούν να αναπαρασταθούν ως εξής:
Εικόνα 6: Μετατροπή βάσης δεδομένων εσωτερικής μορφής σε κανονικοποιημένη βάση δεδομένων
Δηλαδή, αντί για έναν πίνακα, πήραμε μια κανονικοποιημένη βάση δεδομένων. Στην πραγματικότητα, η κανονικοποίηση μειώνει την ταχύτητα του συστήματος, μπορούν να πουν οι ειδικοί της βάσης δεδομένων, και σε αυτό σίγουρα θα έχουν δίκιο, στην περίπτωση που πρέπει να λάβουμε τιμές για στοιχεία λεξικού (στην περίπτωσή μας, τιμές μέτρησης). Αλλά το θέμα είναι ότι δεν χρειαζόμαστε καθόλου αυτές τις τιμές στο στάδιο της κατασκευής της φέτας. Όπως αναφέρθηκε παραπάνω, μας ενδιαφέρουν μόνο οι συντεταγμένες στον υπερκύβο μας, επομένως θα ορίσουμε τις συντεταγμένες για τις τιμές μέτρησης. Το πιο εύκολο πράγμα που μπορείτε να κάνετε είναι να επαναριθμήσετε τις τιμές των στοιχείων. Προκειμένου η αρίθμηση να είναι ξεκάθαρη σε μία διάσταση, ταξινομούμε πρώτα τις λίστες των τιμών των διαστάσεων (λεξικά, σε όρους βάσης δεδομένων) με αλφαβητική σειρά. Επιπλέον, θα επαναριθμήσουμε τα γεγονότα και τα γεγονότα συγκεντρώνονται εκ των προτέρων. Παίρνουμε το παρακάτω διάγραμμα:
Σχήμα 7. Επαναρίθμηση της κανονικοποιημένης βάσης δεδομένων για τον προσδιορισμό των συντεταγμένων των τιμών μέτρησης
Τώρα το μόνο που μένει είναι να συνδέσουμε τα στοιχεία διαφορετικών τραπεζιών μεταξύ τους. Στη θεωρία των σχεσιακών βάσεων δεδομένων, αυτό γίνεται με τη χρήση ειδικών ενδιάμεσων πινάκων. Αρκεί να συσχετίσουμε κάθε καταχώρηση στους πίνακες μετρήσεων με μια λίστα, τα στοιχεία της οποίας θα είναι ο αριθμός των γεγονότων για τον σχηματισμό των οποίων χρησιμοποιήθηκαν αυτές οι μετρήσεις (δηλαδή, για να προσδιορίσουμε όλα τα γεγονότα που έχουν την ίδια τιμή η συντεταγμένη που περιγράφεται από αυτή τη μέτρηση). Για γεγονότα, κάθε εγγραφή θα αντιστοιχιστεί με τις τιμές των συντεταγμένων κατά μήκος των οποίων βρίσκεται στον υπερκύβο. Στο μέλλον, οι συντεταγμένες μιας εγγραφής σε έναν υπερκύβο θα νοούνται ως οι αριθμοί των αντίστοιχων εγγραφών στους πίνακες τιμών μέτρησης. Στη συνέχεια, για το υποθετικό μας παράδειγμα, παίρνουμε το ακόλουθο σύνολο που ορίζει την εσωτερική αναπαράσταση του υπερκύβου:
Διάγραμμα 8. Εσωτερική αναπαράσταση υπερκύβου
Αυτή θα είναι η εσωτερική μας αναπαράσταση του υπερκύβου. Δεδομένου ότι δεν το κάνουμε για μια σχεσιακή βάση δεδομένων, χρησιμοποιούμε απλώς πεδία μεταβλητού μήκους ως πεδία για τη σύνδεση τιμών μέτρησης (δεν θα μπορούσαμε να το κάνουμε αυτό σε ένα RDB, καθώς ο αριθμός των στηλών του πίνακα είναι προκαθορισμένος εκεί).
Θα μπορούσαμε να προσπαθήσουμε να χρησιμοποιήσουμε ένα σύνολο προσωρινών πινάκων για την υλοποίηση του υπερκύβου, αλλά αυτή η μέθοδος θα παρέχει πολύ χαμηλή απόδοση (για παράδειγμα, ένα σύνολο στοιχείων του κύβου απόφασης), επομένως θα χρησιμοποιήσουμε τις δικές μας δομές αποθήκευσης δεδομένων.
Για να υλοποιήσουμε έναν υπερκύβο, πρέπει να χρησιμοποιήσουμε δομές δεδομένων που θα εξασφαλίζουν μέγιστη απόδοση και ελάχιστη κατανάλωση RAM. Προφανώς, οι κύριες δομές μας θα είναι για την αποθήκευση λεξικών και πινάκων γεγονότων. Ας δούμε τις εργασίες που πρέπει να εκτελεί ένα λεξικό με τη μέγιστη ταχύτητα:
έλεγχος της παρουσίας ενός στοιχείου στο λεξικό.
προσθήκη ενός στοιχείου στο λεξικό.
αναζήτηση αριθμών εγγραφής που έχουν συγκεκριμένη τιμή συντεταγμένων.
Αναζήτηση συντεταγμένων με βάση την τιμή μέτρησης.
αναζήτηση μιας τιμής μέτρησης από τη συντεταγμένη της.
Διάφοροι τύποι δεδομένων και δομές μπορούν να χρησιμοποιηθούν για την υλοποίηση αυτών των απαιτήσεων. Για παράδειγμα, μπορείτε να χρησιμοποιήσετε πίνακες δομών. Σε μια πραγματική περίπτωση, αυτοί οι πίνακες απαιτούν πρόσθετους μηχανισμούς ευρετηρίασης που θα αυξήσουν την ταχύτητα φόρτωσης δεδομένων και ανάκτησης πληροφοριών.
Για να βελτιστοποιηθεί η λειτουργία ενός υπερκύβου, είναι απαραίτητο να καθοριστεί ποιες εργασίες πρέπει να επιλυθούν κατά προτεραιότητα και με ποια κριτήρια πρέπει να βελτιώσουμε την ποιότητα της εργασίας. Το κύριο πράγμα για εμάς είναι να αυξήσουμε την ταχύτητα του προγράμματος, ενώ είναι επιθυμητό να απαιτείται όχι πολύ μεγάλη ποσότητα μνήμης RAM. Αυξημένη απόδοση είναι δυνατή μέσω της εισαγωγής πρόσθετων μηχανισμών πρόσβασης σε δεδομένα, για παράδειγμα, με την εισαγωγή της ευρετηρίασης. Δυστυχώς, αυτό αυξάνει την επιβάρυνση της μνήμης RAM. Επομένως, θα καθορίσουμε ποιες λειτουργίες πρέπει να εκτελέσουμε με την υψηλότερη ταχύτητα. Για να το κάνετε αυτό, εξετάστε τα μεμονωμένα στοιχεία που υλοποιούν τον υπερκύβο. Αυτά τα εξαρτήματα έχουν δύο κύριους τύπους - πίνακα διαστάσεων και γεγονότων. Για τη μέτρηση, μια τυπική εργασία θα ήταν:
Προσθέτοντας μια νέα τιμή.
προσδιορισμός της συντεταγμένης με βάση την τιμή μέτρησης.
προσδιορισμός της τιμής με συντεταγμένες.
Όταν προσθέτουμε μια νέα τιμή στοιχείου, πρέπει να ελέγξουμε αν έχουμε ήδη μια τέτοια τιμή και αν ναι, τότε μην προσθέσουμε νέα, αλλά χρησιμοποιούμε την υπάρχουσα συντεταγμένη, διαφορετικά πρέπει να προσθέσουμε ένα νέο στοιχείο και να προσδιορίσουμε τη συντεταγμένη του. Για να το κάνετε αυτό, χρειάζεστε έναν τρόπο για να βρείτε γρήγορα την παρουσία του επιθυμητού στοιχείου (επιπλέον, ένα τέτοιο πρόβλημα προκύπτει κατά τον προσδιορισμό της συντεταγμένης από την τιμή του στοιχείου). Για το σκοπό αυτό, είναι βέλτιστο να χρησιμοποιείτε κατακερματισμό. Σε αυτήν την περίπτωση, η βέλτιστη δομή θα ήταν η χρήση δέντρων κατακερματισμού στα οποία θα αποθηκεύουμε αναφορές σε στοιχεία. Σε αυτήν την περίπτωση, τα στοιχεία θα είναι οι γραμμές του λεξικού διαστάσεων. Στη συνέχεια, η δομή της τιμής μέτρησης μπορεί να αναπαρασταθεί ως εξής:
PFactLink = ^TFactLink;
TFactLink = εγγραφή
FactNo: ακέραιος; // ευρετήριο γεγονότων στον πίνακα
TDimensionRecord = εγγραφή
Τιμή: συμβολοσειρά; // τιμή μέτρησης
Ευρετήριο: ακέραιος; // τιμή συντεταγμένων
FactLink: PFactLink; // δείκτης στην αρχή της λίστας στοιχείων πίνακα γεγονότων
Και στο δέντρο κατακερματισμού θα αποθηκεύσουμε συνδέσμους σε μοναδικά στοιχεία. Επιπλέον, πρέπει να λύσουμε το πρόβλημα του αντίστροφου μετασχηματισμού - χρησιμοποιώντας τη συντεταγμένη για τον προσδιορισμό της τιμής μέτρησης. Για να εξασφαλιστεί η μέγιστη απόδοση, θα πρέπει να χρησιμοποιείται απευθείας διευθυνσιοδότηση. Επομένως, μπορείτε να χρησιμοποιήσετε έναν άλλο πίνακα, το ευρετήριο του οποίου είναι η συντεταγμένη της διάστασης και η τιμή είναι ένας σύνδεσμος προς την αντίστοιχη καταχώρηση στο λεξικό. Ωστόσο, μπορείτε να το κάνετε πιο εύκολα (και να εξοικονομήσετε μνήμη) εάν τακτοποιήσετε τη διάταξη των στοιχείων ανάλογα έτσι ώστε ο δείκτης του στοιχείου να είναι η συντεταγμένη του.
Η οργάνωση ενός πίνακα που υλοποιεί μια λίστα γεγονότων δεν παρουσιάζει ιδιαίτερα προβλήματα λόγω της απλής δομής του. Η μόνη παρατήρηση θα ήταν ότι είναι σκόπιμο να υπολογιστούν όλες οι μέθοδοι συγκέντρωσης που μπορεί να χρειαστούν και οι οποίες μπορούν να υπολογιστούν σταδιακά (για παράδειγμα, άθροισμα).
Έτσι, περιγράψαμε μια μέθοδο αποθήκευσης δεδομένων με τη μορφή υπερκύβου. Σας επιτρέπει να δημιουργήσετε ένα σύνολο σημείων σε έναν πολυδιάστατο χώρο με βάση πληροφορίες που βρίσκονται στην αποθήκη δεδομένων. Προκειμένου ένα άτομο να μπορεί να εργαστεί με αυτά τα δεδομένα, πρέπει να παρουσιάζονται σε μορφή κατάλληλη για επεξεργασία. Σε αυτήν την περίπτωση, ένας συγκεντρωτικός πίνακας και γραφήματα χρησιμοποιούνται ως κύριοι τύποι παρουσίασης δεδομένων. Επιπλέον, και οι δύο αυτές μέθοδοι είναι στην πραγματικότητα προβολές ενός υπερκύβου. Προκειμένου να διασφαλίσουμε τη μέγιστη απόδοση κατά την κατασκευή αναπαραστάσεων, θα ξεκινήσουμε από το τι αντιπροσωπεύουν αυτές οι προβολές. Ας ξεκινήσουμε με τον συγκεντρωτικό πίνακα, ως τον πιο σημαντικό για την ανάλυση δεδομένων.
Ας βρούμε τρόπους να εφαρμόσουμε μια τέτοια δομή. Υπάρχουν τρία μέρη που συνθέτουν έναν συγκεντρωτικό πίνακα: κεφαλίδες σειρών, κεφαλίδες στηλών και ο πραγματικός πίνακας συγκεντρωτικών τιμών γεγονότων. Ο απλούστερος τρόπος για να αναπαραστήσετε έναν πίνακα γεγονότων είναι να χρησιμοποιήσετε έναν δισδιάστατο πίνακα, η διάσταση του οποίου μπορεί να προσδιοριστεί με την κατασκευή των κεφαλίδων. Δυστυχώς, η απλούστερη μέθοδος θα είναι η πιο αναποτελεσματική, επειδή ο πίνακας θα είναι πολύ αραιός και η μνήμη θα χρησιμοποιηθεί εξαιρετικά αναποτελεσματική, με αποτέλεσμα να είναι δυνατή η κατασκευή μόνο πολύ μικρών κύβων, γιατί διαφορετικά μπορεί να μην υπάρχουν αρκετοί μνήμη. Έτσι, πρέπει να επιλέξουμε μια δομή δεδομένων για την αποθήκευση πληροφοριών που θα εξασφαλίζει τη μέγιστη ταχύτητα αναζήτησης/προσθήκης νέου στοιχείου και ταυτόχρονα την ελάχιστη κατανάλωση RAM. Αυτή η δομή θα είναι οι λεγόμενοι αραιοί πίνακες, για τους οποίους μπορείτε να διαβάσετε με περισσότερες λεπτομέρειες από τον Knuth. Υπάρχουν διάφοροι τρόποι οργάνωσης της μήτρας. Για να επιλέξουμε την επιλογή που μας ταιριάζει, θα εξετάσουμε πρώτα τη δομή των κεφαλίδων του πίνακα.
Οι επικεφαλίδες έχουν μια σαφή ιεραρχική δομή, επομένως θα ήταν φυσικό να υποθέσουμε ότι χρησιμοποιείται ένα δέντρο για την αποθήκευσή τους. Σε αυτή την περίπτωση, η δομή ενός κόμβου δέντρου μπορεί να απεικονιστεί σχηματικά ως εξής:
Παράρτημα Γ
Σε αυτήν την περίπτωση, είναι λογικό να αποθηκεύεται ως τιμή διάστασης ένας σύνδεσμος προς το αντίστοιχο στοιχείο του πίνακα διαστάσεων ενός πολυδιάστατου κύβου. Αυτό θα μειώσει το κόστος της μνήμης για την αποθήκευση του slice και θα επιταχύνει την εργασία. Οι σύνδεσμοι χρησιμοποιούνται επίσης ως γονικοί και θυγατρικοί κόμβοι.
Για να προσθέσετε ένα στοιχείο σε ένα δέντρο, πρέπει να έχετε πληροφορίες σχετικά με τη θέση του στον υπερκύβο. Ως τέτοια πληροφορία, πρέπει να χρησιμοποιήσετε τη συντεταγμένη της, η οποία είναι αποθηκευμένη στο λεξικό των τιμών μέτρησης. Ας δούμε το σχήμα για την προσθήκη ενός στοιχείου στο δέντρο κεφαλίδας ενός συγκεντρωτικού πίνακα. Σε αυτήν την περίπτωση, χρησιμοποιούμε τις τιμές των συντεταγμένων μέτρησης ως αρχική πληροφορία. Η σειρά με την οποία παρατίθενται αυτές οι διαστάσεις καθορίζεται από την επιθυμητή μέθοδο συγκέντρωσης και ταιριάζει με τα επίπεδα ιεραρχίας του δέντρου κεφαλίδας. Ως αποτέλεσμα της εργασίας, πρέπει να αποκτήσετε μια λίστα στηλών ή γραμμών του συγκεντρωτικού πίνακα στον οποίο πρέπει να προσθέσετε ένα στοιχείο.
Εφαρμογήρε
Χρησιμοποιούμε συντεταγμένες μέτρησης ως αρχικά δεδομένα για τον προσδιορισμό αυτής της δομής. Επιπλέον, για βεβαιότητα, θα υποθέσουμε ότι ορίζουμε τη στήλη που μας ενδιαφέρει στον πίνακα (θα εξετάσουμε πώς να ορίσουμε μια σειρά λίγο αργότερα, καθώς είναι πιο βολικό να χρησιμοποιούμε άλλες δομές δεδομένων εκεί· ο λόγος για αυτή η επιλογή φαίνεται επίσης παρακάτω). Ως συντεταγμένες, παίρνουμε ακέραιους αριθμούς - αριθμούς τιμών μέτρησης που μπορούν να προσδιοριστούν όπως περιγράφεται παραπάνω.
Έτσι, αφού εκτελέσουμε αυτή τη διαδικασία, θα λάβουμε μια σειρά από αναφορές στις στήλες του αραιού πίνακα. Τώρα πρέπει να εκτελέσετε όλες τις απαραίτητες ενέργειες με τις χορδές. Για να το κάνετε αυτό, πρέπει να βρείτε το απαιτούμενο στοιχείο μέσα σε κάθε στήλη και να προσθέσετε την αντίστοιχη τιμή εκεί. Για κάθε διάσταση στη συλλογή, πρέπει να γνωρίζετε τον αριθμό των μοναδικών τιμών και το πραγματικό σύνολο αυτών των τιμών.
Τώρα ας δούμε τη μορφή με την οποία πρέπει να αντιπροσωπεύονται οι τιμές μέσα στις στήλες - δηλαδή πώς να προσδιορίσετε την απαιτούμενη σειρά. Υπάρχουν πολλές προσεγγίσεις που μπορείτε να χρησιμοποιήσετε για να το πετύχετε. Το απλούστερο θα ήταν να αναπαραστήσετε κάθε στήλη ως διάνυσμα, αλλά επειδή θα είναι πολύ αραιή, η μνήμη θα χρησιμοποιηθεί εξαιρετικά αναποτελεσματική. Για να αποφευχθεί αυτό, θα χρησιμοποιήσουμε δομές δεδομένων που θα παρέχουν μεγαλύτερη αποτελεσματικότητα στην αναπαράσταση αραιών μονοδιάστατων πινάκων (διανύσματα). Το απλούστερο από αυτά θα ήταν μια κανονική λίστα, μεμονωμένη ή διπλά συνδεδεμένη, αλλά είναι αντιοικονομική από την άποψη της πρόσβασης σε στοιχεία. Επομένως, θα χρησιμοποιήσουμε ένα δέντρο, το οποίο θα παρέχει ταχύτερη πρόσβαση σε στοιχεία.
Για παράδειγμα, θα μπορούσατε να χρησιμοποιήσετε ακριβώς το ίδιο δέντρο όπως για τις στήλες, αλλά στη συνέχεια θα πρέπει να δημιουργήσετε το δικό σας δέντρο για κάθε στήλη, το οποίο θα οδηγούσε σε σημαντική επιβάρυνση μνήμης και χρόνο επεξεργασίας. Ας το κάνουμε λίγο πιο πονηρά - θα δημιουργήσουμε ένα δέντρο για να αποθηκεύουμε όλους τους συνδυασμούς διαστάσεων που χρησιμοποιούνται σε συμβολοσειρές, οι οποίοι θα είναι πανομοιότυποι με αυτόν που περιγράφηκε παραπάνω, αλλά τα στοιχεία του δεν θα είναι δείκτες σε συμβολοσειρές (που δεν υπάρχουν ως τέτοιοι ), αλλά οι δείκτες τους και οι ίδιες οι τιμές των δεικτών δεν μας ενδιαφέρουν και χρησιμοποιούνται μόνο ως μοναδικά κλειδιά. Στη συνέχεια, θα χρησιμοποιήσουμε αυτά τα κλειδιά για να βρούμε το επιθυμητό στοιχείο μέσα στη στήλη. Οι ίδιες οι στήλες αναπαρίστανται πιο εύκολα ως ένα κανονικό δυαδικό δέντρο. Γραφικά, η δομή που προκύπτει μπορεί να αναπαρασταθεί ως εξής:
Διάγραμμα 9. Εικόνα συγκεντρωτικού πίνακα ως δυαδικό δέντρο
Μπορείτε να χρησιμοποιήσετε την ίδια διαδικασία με τη διαδικασία που περιγράφεται παραπάνω για τον προσδιορισμό των στηλών του συγκεντρωτικού πίνακα για να προσδιορίσετε τους κατάλληλους αριθμούς σειρών. Σε αυτήν την περίπτωση, οι αριθμοί σειρών είναι μοναδικοί σε έναν συγκεντρωτικό πίνακα και προσδιορίζουν στοιχεία σε διανύσματα που είναι στήλες του συγκεντρωτικού πίνακα. Η απλούστερη επιλογή για τη δημιουργία αυτών των αριθμών θα ήταν να διατηρήσετε έναν μετρητή και να τον αυξήσετε κατά ένα κατά την προσθήκη ενός νέου στοιχείου στο δέντρο κεφαλίδας σειράς. Αυτά τα ίδια τα διανύσματα στηλών αποθηκεύονται πιο εύκολα ως δυαδικά δέντρα, όπου η τιμή του αριθμού σειράς χρησιμοποιείται ως κλειδί. Επιπλέον, είναι επίσης δυνατή η χρήση πινάκων κατακερματισμού. Δεδομένου ότι οι διαδικασίες εργασίας με αυτά τα δέντρα συζητούνται λεπτομερώς σε άλλες πηγές, δεν θα σταθούμε σε αυτό και θα εξετάσουμε το γενικό σχήμα για την προσθήκη ενός στοιχείου σε μια στήλη.
Γενικά, η ακολουθία ενεργειών για την προσθήκη ενός στοιχείου στον πίνακα μπορεί να περιγραφεί ως εξής:
1. Προσδιορίστε τους αριθμούς γραμμών στους οποίους προστίθενται στοιχεία
2.Ορίστε ένα σύνολο στηλών στις οποίες προστίθενται στοιχεία
3. Για όλες τις στήλες, βρείτε τα στοιχεία με τους απαιτούμενους αριθμούς σειρών και προσθέστε το τρέχον στοιχείο σε αυτά (η προσθήκη περιλαμβάνει τη σύνδεση του απαιτούμενου αριθμού τιμών γεγονότων και τον υπολογισμό συγκεντρωτικών τιμών, που μπορούν να προσδιοριστούν σταδιακά).
Αφού εκτελέσουμε αυτόν τον αλγόριθμο, θα λάβουμε έναν πίνακα, ο οποίος είναι ένας συνοπτικός πίνακας που χρειαζόμασταν να δημιουργήσουμε.
Τώρα λίγα λόγια για το φιλτράρισμα κατά την κατασκευή μιας φέτας. Ο ευκολότερος τρόπος για να γίνει αυτό είναι στο στάδιο της κατασκευής του πίνακα, καθώς σε αυτό το στάδιο υπάρχει πρόσβαση σε όλα τα απαιτούμενα πεδία και, επιπλέον, πραγματοποιείται συνάθροιση τιμών. Σε αυτήν την περίπτωση, κατά την ανάκτηση μιας καταχώρησης από τη μνήμη cache, ελέγχεται η συμμόρφωσή της με τις συνθήκες φιλτραρίσματος και εάν δεν πληρούται, η καταχώριση απορρίπτεται.
Δεδομένου ότι η δομή που περιγράφεται παραπάνω περιγράφει πλήρως τον πίνακα περιστροφής, το έργο της οπτικοποίησής του θα είναι ασήμαντο. Σε αυτήν την περίπτωση, μπορείτε να χρησιμοποιήσετε τυπικά στοιχεία πίνακα που είναι διαθέσιμα σε όλα σχεδόν τα εργαλεία προγραμματισμού για Windows.
Το πρώτο προϊόν που πραγματοποίησε ερωτήματα OLAP ήταν το Express (IRI). Ωστόσο, ο ίδιος ο όρος OLAP επινοήθηκε από τον Edgar Codd, «τον πατέρα των σχεσιακών βάσεων δεδομένων». Και το έργο του Codd χρηματοδοτήθηκε από την Arbor, μια εταιρεία που είχε κυκλοφορήσει το δικό της προϊόν OLAP, Essbase (αργότερα εξαγοράστηκε από την Hyperion, η οποία εξαγοράστηκε από την Oracle το 2007) το προηγούμενο έτος. Άλλα γνωστά προϊόντα OLAP περιλαμβάνουν τις Υπηρεσίες ανάλυσης Microsoft (παλαιότερα ονομαζόμενες Υπηρεσίες OLAP, μέρος του SQL Server), το Oracle OLAP Option, τον διακομιστή DB2 OLAP της IBM (ουσιαστικά EssBase με προσθήκες από την IBM), SAP BW, προϊόντα Brio, BusinessObjects, Cognos, MicroStrategy και άλλους κατασκευαστές.
Από τεχνικής άποψης, τα προϊόντα που κυκλοφορούν στην αγορά χωρίζονται σε «φυσικό OLAP» και «εικονικό». Στην πρώτη περίπτωση, υπάρχει ένα πρόγραμμα που εκτελεί έναν προκαταρκτικό υπολογισμό αδρανών, τα οποία στη συνέχεια αποθηκεύονται σε μια ειδική πολυδιάστατη βάση δεδομένων που παρέχει γρήγορη ανάκτηση. Παραδείγματα τέτοιων προϊόντων είναι οι Υπηρεσίες ανάλυσης της Microsoft, το Oracle OLAP Option, το Oracle/Hyperion EssBase, το Cognos PowerPlay. Στη δεύτερη περίπτωση, τα δεδομένα αποθηκεύονται σε σχεσιακά DBMS και τα συγκεντρωτικά στοιχεία μπορεί να μην υπάρχουν καθόλου ή μπορεί να δημιουργηθούν με το πρώτο αίτημα στο DBMS ή στην κρυφή μνήμη του αναλυτικού λογισμικού. Παραδείγματα τέτοιων προϊόντων είναι τα SAP BW, BusinessObjects, Microstrategy. Τα συστήματα που βασίζονται σε "φυσικό OLAP" παρέχουν σταθερά καλύτερους χρόνους απόκρισης σε ερωτήματα από τα συστήματα "εικονικού OLAP". Οι πωλητές εικονικών OLAP ισχυρίζονται μεγαλύτερη επεκτασιμότητα των προϊόντων τους για να υποστηρίζουν πολύ μεγάλους όγκους δεδομένων.
Σε αυτήν την εργασία, θα ήθελα να ρίξω μια πιο προσεκτική ματιά στο προϊόν BaseGroup Labs - Deductor.
Το Deductor είναι μια πλατφόρμα ανάλυσης, δηλ. βάση για τη δημιουργία ολοκληρωμένων λύσεων εφαρμογής. Οι τεχνολογίες που εφαρμόζονται στο Deductor σάς επιτρέπουν να περάσετε από όλα τα στάδια της κατασκευής ενός αναλυτικού συστήματος με βάση μια ενιαία αρχιτεκτονική: από τη δημιουργία μιας αποθήκης δεδομένων έως την αυτόματη επιλογή μοντέλων και την οπτικοποίηση των αποτελεσμάτων που λαμβάνονται.
Σύνθεση συστήματος:
Το Deductor Studio είναι ο αναλυτικός πυρήνας της πλατφόρμας Deductor. Το Deductor Studio περιλαμβάνει ένα πλήρες σύνολο μηχανισμών που σας επιτρέπει να λαμβάνετε πληροφορίες από μια αυθαίρετη πηγή δεδομένων, να πραγματοποιείτε ολόκληρο τον κύκλο επεξεργασίας (καθαρισμός, μετατροπή δεδομένων, κατασκευή μοντέλων), να εμφανίζετε τα αποτελέσματα με τον πιο βολικό τρόπο (OLAP, πίνακες, γραφήματα , δέντρα αποφάσεων...) και αποτελέσματα εξαγωγής.
Το Deductor Viewer είναι ο σταθμός εργασίας του τελικού χρήστη. Το πρόγραμμα σας επιτρέπει να ελαχιστοποιήσετε τις απαιτήσεις για το προσωπικό, επειδή όλες οι απαιτούμενες λειτουργίες εκτελούνται αυτόματα χρησιμοποιώντας προηγουμένως προετοιμασμένα σενάρια επεξεργασίας· δεν χρειάζεται να σκεφτόμαστε τη μέθοδο απόκτησης δεδομένων και τους μηχανισμούς επεξεργασίας τους. Ο χρήστης του Dedustor Viewer χρειάζεται μόνο να επιλέξει την αναφορά που ενδιαφέρει.
Το Deductor Warehouse είναι μια πολυδιάστατη αποθήκη δεδομένων πολλαπλών πλατφορμών που συγκεντρώνει όλες τις απαραίτητες πληροφορίες για την ανάλυση της θεματικής περιοχής. Η χρήση ενός μόνο αποθετηρίου επιτρέπει την εύκολη πρόσβαση, υψηλή ταχύτητα επεξεργασίας, συνέπεια των πληροφοριών, κεντρική αποθήκευση και αυτόματη υποστήριξη για ολόκληρη τη διαδικασία ανάλυσης δεδομένων.
4. Client-Server
Ο Deductor Server έχει σχεδιαστεί για απομακρυσμένη αναλυτική επεξεργασία. Παρέχει τη δυνατότητα αυτόματης «εκτέλεσης» δεδομένων μέσω υπαρχόντων σεναρίων στο διακομιστή και επανεκπαίδευσης υπαρχόντων μοντέλων. Η χρήση του Deductor Server σάς επιτρέπει να εφαρμόσετε μια ολοκληρωμένη αρχιτεκτονική τριών επιπέδων στην οποία λειτουργεί ως διακομιστής εφαρμογών. Η πρόσβαση στον διακομιστή παρέχεται χρησιμοποιώντας το Deductor Client.
Αρχές εργασίας:
1. Εισαγωγή δεδομένων
Η ανάλυση οποιασδήποτε πληροφορίας στο Deductor ξεκινά με την εισαγωγή δεδομένων. Ως αποτέλεσμα της εισαγωγής, τα δεδομένα μεταφέρονται σε μορφή κατάλληλη για μεταγενέστερη ανάλυση χρησιμοποιώντας όλους τους μηχανισμούς που είναι διαθέσιμοι στο πρόγραμμα. Η φύση των δεδομένων, η μορφή, το DBMS κ.λπ. δεν έχουν σημασία, γιατί οι μηχανισμοί συνεργασίας με όλους είναι ενιαίοι.
2. Εξαγωγή δεδομένων
Η παρουσία μηχανισμών εξαγωγής σάς επιτρέπει να στέλνετε τα αποτελέσματα που λαμβάνονται σε εφαρμογές τρίτων, για παράδειγμα, να μεταφέρετε μια πρόβλεψη πωλήσεων στο σύστημα για να δημιουργήσετε μια παραγγελία αγοράς ή να δημοσιεύσετε την προετοιμασμένη αναφορά σε εταιρικό ιστότοπο.
3. Επεξεργασία δεδομένων
Επεξεργασία στο Deductor σημαίνει οποιαδήποτε ενέργεια που σχετίζεται με κάποιο είδος μετασχηματισμού δεδομένων, για παράδειγμα, φιλτράρισμα, κατασκευή μοντέλου, καθαρισμός κ.λπ. Στην πραγματικότητα, σε αυτό το μπλοκ εκτελούνται οι πιο σημαντικές ενέργειες από την άποψη της ανάλυσης. Το πιο σημαντικό χαρακτηριστικό των μηχανισμών επεξεργασίας που εφαρμόζονται στο Deductor είναι ότι τα δεδομένα που λαμβάνονται ως αποτέλεσμα της επεξεργασίας μπορούν να υποβληθούν σε επεξεργασία ξανά με οποιαδήποτε από τις μεθόδους που είναι διαθέσιμες στο σύστημα. Έτσι, μπορείτε να δημιουργήσετε αυθαίρετα πολύπλοκα σενάρια επεξεργασίας.
4. Οπτικοποίηση
Μπορείτε να οπτικοποιήσετε δεδομένα στο Deductor Studio (Viewer) σε οποιοδήποτε στάδιο της επεξεργασίας. Το σύστημα καθορίζει ανεξάρτητα πώς μπορεί να το κάνει αυτό, για παράδειγμα, εάν ένα νευρωνικό δίκτυο είναι εκπαιδευμένο, τότε εκτός από πίνακες και διαγράμματα, μπορείτε να προβάλετε το γράφημα του νευρικού δικτύου. Ο χρήστης πρέπει να επιλέξει την επιθυμητή επιλογή από τη λίστα και να διαμορφώσει πολλές παραμέτρους.
5. Μηχανισμοί ολοκλήρωσης
Το Deductor δεν παρέχει εργαλεία εισαγωγής δεδομένων - η πλατφόρμα επικεντρώνεται αποκλειστικά στην αναλυτική επεξεργασία. Για τη χρήση πληροφοριών που είναι αποθηκευμένες σε ετερογενή συστήματα, παρέχονται ευέλικτοι μηχανισμοί εισαγωγής-εξαγωγής. Η αλληλεπίδραση μπορεί να οργανωθεί χρησιμοποιώντας εκτέλεση δέσμης, εργασία σε λειτουργία διακομιστή OLE και πρόσβαση στον διακομιστή Deductor.
6.Αναπαραγωγή της γνώσης
Το Deductor σάς επιτρέπει να εφαρμόσετε μια από τις πιο σημαντικές λειτουργίες οποιουδήποτε αναλυτικού συστήματος - υποστήριξη για τη διαδικασία αναπαραγωγής γνώσης, δηλ. παρέχοντας την ευκαιρία σε υπαλλήλους που δεν κατανοούν τις μεθόδους ανάλυσης και τις μεθόδους απόκτησης ενός συγκεκριμένου αποτελέσματος να λάβουν μια απάντηση βάσει μοντέλων που έχει προετοιμάσει ένας ειδικός.
Ζσυμπέρασμα
Αυτή η εργασία εξέτασε έναν τέτοιο τομέα των σύγχρονων τεχνολογιών πληροφοριών όπως τα συστήματα ανάλυσης δεδομένων. Αναλύεται το κύριο εργαλείο για την αναλυτική επεξεργασία πληροφοριών - τεχνολογία OLAP. Η ουσία της έννοιας του OLAP και η σημασία των συστημάτων OLAP σε μια σύγχρονη επιχειρηματική διαδικασία αποκαλύπτονται λεπτομερώς. Η δομή και η διαδικασία λειτουργίας ενός διακομιστή ROLAP περιγράφεται αναλυτικά. Ως παράδειγμα εφαρμογής των τεχνολογιών δεδομένων OLAP, δίνεται η αναλυτική πλατφόρμα Deductor. Η υποβληθείσα τεκμηρίωση έχει αναπτυχθεί και πληροί τις απαιτήσεις.
Οι τεχνολογίες OLAP είναι ένα ισχυρό εργαλείο για την επεξεργασία δεδομένων σε πραγματικό χρόνο. Ένας διακομιστής OLAP σάς επιτρέπει να οργανώνετε και να παρουσιάζετε δεδομένα σε διάφορους αναλυτικούς τομείς και μετατρέπει τα δεδομένα σε πολύτιμες πληροφορίες που βοηθούν τις εταιρείες να λαμβάνουν πιο ενημερωμένες αποφάσεις.
Η χρήση συστημάτων OLAP παρέχει σταθερά υψηλά επίπεδα απόδοσης και επεκτασιμότητας, υποστηρίζοντας όγκους δεδομένων πολλών gigabyte στους οποίους μπορούν να έχουν πρόσβαση χιλιάδες χρήστες. Με τη βοήθεια των τεχνολογιών OLAP, η πρόσβαση στις πληροφορίες πραγματοποιείται σε πραγματικό χρόνο, δηλ. Η επεξεργασία ερωτημάτων δεν επιβραδύνει πλέον τη διαδικασία ανάλυσης, διασφαλίζοντας την ταχύτητα και την αποτελεσματικότητά της. Τα εργαλεία οπτικής διαχείρισης σάς επιτρέπουν να αναπτύσσετε και να εφαρμόζετε ακόμη και τις πιο σύνθετες αναλυτικές εφαρμογές, κάνοντας τη διαδικασία απλή και γρήγορη.
Παρόμοια έγγραφα
Η βάση της έννοιας του OLAP (On-Line Analytical Processing) είναι η επιχειρησιακή αναλυτική επεξεργασία δεδομένων, τα χαρακτηριστικά της χρήσης του στον πελάτη και στον διακομιστή. Γενικά χαρακτηριστικά των βασικών απαιτήσεων για συστήματα OLAP, καθώς και μέθοδοι αποθήκευσης δεδομένων σε αυτά.
περίληψη, προστέθηκε 10/12/2010
OLAP: γενικά χαρακτηριστικά, σκοπός, στόχοι, στόχοι. Ταξινόμηση προϊόντων OLAP. Αρχές κατασκευής συστήματος OLAP, βιβλιοθήκη στοιχείων CubeBase. Εξάρτηση της απόδοσης των εργαλείων OLAP πελάτη και διακομιστή από την αύξηση του όγκου δεδομένων.
εργασία μαθήματος, προστέθηκε 25/12/2013
Αιώνια αποθήκευση δεδομένων. Η ουσία και η σημασία του εργαλείου OLAP (On-line Analytical Processing). Βάσεις δεδομένων και αποθήκες δεδομένων, τα χαρακτηριστικά τους. Δομή, αρχιτεκτονική αποθήκευσης δεδομένων, προμηθευτές τους. Μερικές συμβουλές για τη βελτίωση της απόδοσης των κύβων OLAP.
δοκιμή, προστέθηκε στις 23/10/2010
Κατασκευή συστημάτων ανάλυσης δεδομένων. Δημιουργία αλγορίθμων για το σχεδιασμό ενός κύβου OLAP και τη δημιουργία ερωτημάτων για τον κατασκευασμένο πίνακα περιστροφής. Τεχνολογία OLAP για πολυδιάστατη ανάλυση δεδομένων. Παροχή πληροφοριών στους χρήστες για τη λήψη αποφάσεων διαχείρισης.
εργασία μαθήματος, προστέθηκε 19/09/2008
Βασικές πληροφορίες για το OLAP. Λειτουργική αναλυτική επεξεργασία δεδομένων. Ταξινόμηση προϊόντων OLAP. Απαιτήσεις για ηλεκτρονικά εργαλεία αναλυτικής επεξεργασίας. Η χρήση πολυδιάστατων βάσεων δεδομένων σε συστήματα επιχειρησιακής αναλυτικής επεξεργασίας, τα πλεονεκτήματά τους.
εργασία μαθήματος, προστέθηκε 06/10/2011
Ανάπτυξη υποσυστημάτων ανάλυσης ιστοσελίδων με χρήση τεχνολογιών Microsoft Access και Olap. Θεωρητικές πτυχές ανάπτυξης ενός υποσυστήματος ανάλυσης δεδομένων στο πληροφοριακό σύστημα μιας μουσικής πύλης. Οι τεχνολογίες Olap στο υποσύστημα ανάλυσης αντικειμένων έρευνας.
εργασία μαθήματος, προστέθηκε 11/06/2009
Εξέταση των εργαλείων OLAP: ταξινόμηση βιτρινών και αποθηκών πληροφοριών, η έννοια ενός κύβου δεδομένων. Αρχιτεκτονική ενός συστήματος υποστήριξης αποφάσεων. Εφαρμογή λογισμικού του συστήματος «Abitura». Δημιουργία αναφοράς Ιστού χρησιμοποιώντας τεχνολογίες Υπηρεσιών Αναφοράς.
εργασία μαθήματος, προστέθηκε 12/05/2012
Αποθήκευση δεδομένων, αρχές οργάνωσης. Διαδικασίες για εργασία με δεδομένα. Δομή OLAP, τεχνικές πτυχές της πολυδιάστατης αποθήκευσης δεδομένων. Υπηρεσίες ολοκλήρωσης, συμπλήρωση αποθηκών δεδομένων και μάρκετ δεδομένων. Δυνατότητες συστημάτων που χρησιμοποιούν τεχνολογίες Microsoft.
εργασία μαθήματος, προστέθηκε 12/05/2012
Κατασκευή διαγράμματος αποθήκης δεδομένων για εμπορική επιχείρηση. Περιγραφές διαγραμμάτων σχέσεων αποθήκευσης. Εμφάνιση πληροφοριών προϊόντος. Δημιουργία κύβου OLAP για περαιτέρω ανάλυση πληροφοριών. Ανάπτυξη ερωτημάτων για την αξιολόγηση της αποτελεσματικότητας ενός σούπερ μάρκετ.
δοκιμή, προστέθηκε στις 19/12/2015
Σκοπός αποθήκευσης δεδομένων. Αρχιτεκτονική SAP BW. Δημιουργία αναλυτικών αναφορών με βάση τους κύβους OLAP στο σύστημα SAP BW. Βασικές διαφορές μεταξύ μιας αποθήκης δεδομένων και ενός συστήματος OLTP. Επισκόπηση των λειτουργικών περιοχών BEx. Δημιουργία ερωτήματος στο BEx Query Designer.
Ο μηχανισμός OLAP είναι μια από τις δημοφιλείς μεθόδους ανάλυσης δεδομένων σήμερα. Υπάρχουν δύο κύριες προσεγγίσεις για την επίλυση αυτού του προβλήματος. Το πρώτο από αυτά ονομάζεται Multidimensional OLAP (MOLAP) - υλοποίηση του μηχανισμού χρησιμοποιώντας μια πολυδιάστατη βάση δεδομένων στην πλευρά του διακομιστή και το δεύτερο Relational OLAP (ROLAP) - κατασκευή κύβων εν κινήσει με βάση ερωτήματα SQL σε ένα σχεσιακό DBMS. Κάθε μία από αυτές τις προσεγγίσεις έχει τα υπέρ και τα κατά της. Η συγκριτική τους ανάλυση ξεφεύγει από το σκοπό αυτού του άρθρου. Θα περιγράψουμε την υλοποίηση του πυρήνα της μονάδας ROLAP για επιτραπέζιους υπολογιστές.
Αυτή η εργασία προέκυψε μετά τη χρήση ενός συστήματος ROLAP που δημιουργήθηκε με βάση τα στοιχεία του κύβου απόφασης που περιλαμβάνονται στο Borland Delphi. Δυστυχώς, η χρήση αυτού του συνόλου στοιχείων έδειξε κακή απόδοση σε μεγάλους όγκους δεδομένων. Αυτό το πρόβλημα μπορεί να μετριαστεί προσπαθώντας να αποκόψετε όσο το δυνατόν περισσότερα δεδομένα πριν τα τροφοδοτήσετε σε κύβους. Αλλά αυτό δεν είναι πάντα αρκετό.
Μπορείτε να βρείτε πολλές πληροφορίες για τα συστήματα OLAP στο Διαδίκτυο και στον Τύπο, αλλά σχεδόν πουθενά δεν αναφέρεται πώς λειτουργεί στο εσωτερικό του. Επομένως, η λύση στα περισσότερα προβλήματα μας δόθηκε με δοκιμή και λάθος.
Σχέδιο εργασίας
Το γενικό σχήμα λειτουργίας ενός επιτραπέζιου συστήματος OLAP μπορεί να αναπαρασταθεί ως εξής:
Ο αλγόριθμος λειτουργίας είναι ο εξής:
- Λήψη δεδομένων με τη μορφή ενός επίπεδου πίνακα ή ως αποτέλεσμα της εκτέλεσης ενός ερωτήματος SQL.
- Αποθήκευση δεδομένων στην κρυφή μνήμη και μετατροπή τους σε πολυδιάστατο κύβο.
- Εμφάνιση του κατασκευασμένου κύβου με χρήση καρτέλας ή γραφήματος κ.λπ. Γενικά, ένας αυθαίρετος αριθμός προβολών μπορεί να συνδεθεί σε έναν κύβο.
Ας εξετάσουμε πώς μπορεί να διευθετηθεί εσωτερικά ένα τέτοιο σύστημα. Θα ξεκινήσουμε από την πλευρά που φαίνεται και αγγίζεται, δηλαδή από τις οθόνες.
Οι οθόνες που χρησιμοποιούνται στα συστήματα OLAP συνήθως διατίθενται σε δύο τύπους: cross-tabs και γραφήματα. Ας δούμε μια διασταύρωση, η οποία είναι ο βασικός και πιο συνηθισμένος τρόπος εμφάνισης ενός κύβου.
Σταυρός τραπέζι
Στο παρακάτω σχήμα, οι σειρές και οι στήλες που περιέχουν συγκεντρωτικά αποτελέσματα εμφανίζονται με κίτρινο, τα κελιά που περιέχουν στοιχεία είναι με ανοιχτό γκρι και τα κελιά που περιέχουν δεδομένα διαστάσεων είναι με σκούρο γκρι.

Έτσι, ο πίνακας μπορεί να χωριστεί στα ακόλουθα στοιχεία, με τα οποία θα εργαστούμε στο μέλλον:

Όταν συμπληρώνουμε τον πίνακα με γεγονότα, πρέπει να προχωρήσουμε ως εξής:
- Με βάση τα δεδομένα μέτρησης, προσδιορίστε τις συντεταγμένες του στοιχείου που θα προστεθεί στον πίνακα.
- Προσδιορίστε τις συντεταγμένες των στηλών και των γραμμών των συνόλων που επηρεάζονται από το προστιθέμενο στοιχείο.
- Προσθέστε ένα στοιχείο στον πίνακα και τις αντίστοιχες συνολικές στήλες και γραμμές.
Θα πρέπει να σημειωθεί ότι η μήτρα που θα προκύψει θα είναι πολύ αραιή, γι' αυτό και η οργάνωσή της με τη μορφή δισδιάστατου πίνακα (η επιλογή που βρίσκεται στην επιφάνεια) είναι όχι μόνο παράλογη, αλλά, πιθανότατα, αδύνατη λόγω του μεγάλου διάσταση αυτού του πίνακα, για την αποθήκευση του οποίου δεν υπάρχει Δεν αρκεί η ποσότητα μνήμης RAM. Για παράδειγμα, εάν ο κύβος μας περιέχει πληροφορίες σχετικά με τις πωλήσεις για ένα έτος και εάν έχει μόνο 3 διαστάσεις - Πελάτες (250), Προϊόντα (500) και Ημερομηνία (365), τότε θα λάβουμε έναν πίνακα γεγονότων με τις ακόλουθες διαστάσεις:
Αριθμός στοιχείων = 250 x 500 x 365 = 45.625.000
Και αυτό παρά το γεγονός ότι μπορεί να υπάρχουν μόνο μερικές χιλιάδες γεμάτα στοιχεία στη μήτρα. Επιπλέον, όσο μεγαλύτερος είναι ο αριθμός των διαστάσεων, τόσο πιο αραιός θα είναι ο πίνακας.
Επομένως, για να εργαστείτε με αυτόν τον πίνακα, πρέπει να χρησιμοποιήσετε ειδικούς μηχανισμούς για εργασία με αραιούς πίνακες. Είναι δυνατές διάφορες επιλογές για την οργάνωση μιας αραιής μήτρας. Περιγράφονται αρκετά καλά στη βιβλιογραφία προγραμματισμού, για παράδειγμα, στον πρώτο τόμο του κλασικού βιβλίου «The Art of Programming» του Donald Knuth.
Ας εξετάσουμε τώρα πώς μπορούμε να προσδιορίσουμε τις συντεταγμένες ενός γεγονότος, γνωρίζοντας τις διαστάσεις που αντιστοιχούν σε αυτό. Για να γίνει αυτό, ας ρίξουμε μια πιο προσεκτική ματιά στη δομή της κεφαλίδας:
Σε αυτήν την περίπτωση, μπορείτε εύκολα να βρείτε έναν τρόπο να προσδιορίσετε τους αριθμούς του αντίστοιχου κελιού και τα σύνολα στα οποία εμπίπτει. Εδώ μπορούν να προταθούν διάφορες προσεγγίσεις. Ένα από αυτά είναι να χρησιμοποιήσετε ένα δέντρο για να βρείτε τα αντίστοιχα κελιά. Αυτό το δέντρο μπορεί να κατασκευαστεί διασχίζοντας την επιλογή. Επιπλέον, ένας αναλυτικός τύπος επανάληψης μπορεί εύκολα να οριστεί για τον υπολογισμό της απαιτούμενης συντεταγμένης.
Προετοιμασία δεδομένων
Τα δεδομένα που είναι αποθηκευμένα στον πίνακα πρέπει να μετασχηματιστούν για να χρησιμοποιηθούν. Έτσι, για να βελτιωθεί η απόδοση κατά την κατασκευή ενός υπερκύβου, είναι επιθυμητό να βρεθούν μοναδικά στοιχεία αποθηκευμένα σε στήλες που έχουν διαστάσεις του κύβου. Επιπλέον, μπορείτε να πραγματοποιήσετε προκαταρκτική συγκέντρωση γεγονότων για εγγραφές που έχουν τις ίδιες τιμές διαστάσεων. Όπως αναφέρθηκε παραπάνω, οι μοναδικές τιμές που είναι διαθέσιμες στα πεδία μέτρησης είναι σημαντικές για εμάς. Στη συνέχεια μπορεί να προταθεί η ακόλουθη δομή για την αποθήκευσή τους:

Χρησιμοποιώντας αυτή τη δομή, μειώνουμε σημαντικά την απαίτηση μνήμης. Κάτι που είναι αρκετά σχετικό, γιατί... Για να αυξήσετε την ταχύτητα λειτουργίας, συνιστάται η αποθήκευση δεδομένων στη μνήμη RAM. Επιπλέον, μπορείτε να αποθηκεύσετε μόνο μια σειρά στοιχείων και να αποθέσετε τις τιμές τους στο δίσκο, καθώς θα τα χρειαστούμε μόνο όταν εμφανίζουμε τη διασταύρωση.
CubeBase Component Library
Οι ιδέες που περιγράφονται παραπάνω ήταν η βάση για τη δημιουργία της βιβλιοθήκης στοιχείων CubeBase.

TCubeSourceπραγματοποιεί προσωρινή αποθήκευση και μετατροπή δεδομένων σε εσωτερική μορφή, καθώς και προκαταρκτική συγκέντρωση δεδομένων. Συστατικό TCubeEngineπραγματοποιεί υπολογισμούς του υπερκύβου και πράξεις με αυτόν. Στην πραγματικότητα, είναι μια μηχανή OLAP που μετατρέπει ένα επίπεδο τραπέζι σε ένα πολυδιάστατο σύνολο δεδομένων. Συστατικό TCubeGridεμφανίζει τη διασταύρωση και ελέγχει την εμφάνιση του υπερκύβου. TCCubeChartσας επιτρέπει να δείτε τον υπερκύβο με τη μορφή γραφημάτων και το στοιχείο TCubePivoteελέγχει τη λειτουργία του πυρήνα του κύβου.
Σύγκριση απόδοσης
Αυτό το σύνολο εξαρτημάτων έδειξε πολύ υψηλότερη απόδοση από το Decision Cube. Έτσι, σε ένα σύνολο 45 χιλιάδων εγγραφών, τα στοιχεία του κύβου απόφασης απαιτούσαν 8 λεπτά. για την κατασκευή ενός πίνακα περιστροφής. Το CubeBase φόρτωσε δεδομένα σε 7 δευτερόλεπτα. και κατασκευή ενός πίνακα περιστροφής σε 4 δευτερόλεπτα. Κατά τη δοκιμή σε 700 χιλιάδες εγγραφές του κύβου απόφασης, δεν λάβαμε απάντηση εντός 30 λεπτών, μετά την οποία ακυρώσαμε την εργασία. Το CubeBase φόρτωσε δεδομένα σε 45 δευτερόλεπτα. και χτίζοντας έναν κύβο σε 15 δευτερόλεπτα.
Σε όγκους δεδομένων χιλιάδων εγγραφών, το CubeBase επεξεργάστηκε δεκάδες φορές πιο γρήγορα από το Decision Cube. Σε τραπέζια με εκατοντάδες χιλιάδες δίσκους - εκατοντάδες φορές πιο γρήγορα. Και η υψηλή απόδοση είναι ένας από τους πιο σημαντικούς δείκτες των συστημάτων OLAP.
OLAP(από το αγγλικό OnLine Analytical Processing - επιχειρησιακή αναλυτική επεξεργασία δεδομένων, επίσης: αναλυτική επεξεργασία δεδομένων σε πραγματικό χρόνο, διαδραστική αναλυτική επεξεργασία δεδομένων) - μια προσέγγιση για την αναλυτική επεξεργασία δεδομένων με βάση τους πολυδιάστατηιεραρχική αναπαράσταση, η οποία εντάσσεται στον ευρύτερο τομέα της πληροφορικής – επιχειρηματικής ανάλυσης ().
Για έναν κατάλογο λύσεων και έργων OLAP, δείτε την ενότητα OLAPστο TAdviser.
Από την πλευρά του χρήστη, OLAP-τα συστήματα παρέχουν εργαλεία για ευέλικτη προβολή πληροφοριών σε διάφορες ενότητες, αυτόματη λήψη συγκεντρωτικών δεδομένων, εκτέλεση αναλυτικών λειτουργιών συνέλιξης, λεπτομερειών και σύγκρισης με την πάροδο του χρόνου. Όλα αυτά καθιστούν τα συστήματα OLAP μια λύση με προφανή πλεονεκτήματα στον τομέα της προετοιμασίας δεδομένων για όλους τους τύπους επιχειρηματικών αναφορών, που περιλαμβάνει την παρουσίαση δεδομένων σε διάφορες ενότητες και διαφορετικά επίπεδα ιεραρχίας - για παράδειγμα, αναφορές πωλήσεων, διάφορες μορφές προϋπολογισμών κ.λπ. επί. Τα πλεονεκτήματα μιας τέτοιας αναπαράστασης σε άλλες μορφές ανάλυσης δεδομένων, συμπεριλαμβανομένης της πρόβλεψης, είναι προφανή.
Απαιτήσεις για συστήματα OLAP. ΦΑΣΜΗ
Η βασική απαίτηση για τα συστήματα OLAP είναι η ταχύτητα, η οποία τους επιτρέπει να χρησιμοποιηθούν στη διαδικασία της διαδραστικής εργασίας ενός αναλυτή με πληροφορίες. Με αυτή την έννοια, τα συστήματα OLAP αντιπαραβάλλονται, πρώτον, με τα παραδοσιακά RDBMS, δείγματα από τα οποία με τυπικά ερωτήματα για αναλυτές που χρησιμοποιούν ομαδοποίηση και συνάθροιση δεδομένων είναι συνήθως ακριβά όσον αφορά τον χρόνο αναμονής και τη φόρτωση RDBMS, επομένως η διαδραστική εργασία μαζί τους με οποιοδήποτε σημαντικό όγκο δεδομένων είναι δύσκολη. Δεύτερον, τα συστήματα OLAP αντιτίθενται επίσης στη συνήθη παρουσίαση δεδομένων σε επίπεδο αρχείο, για παράδειγμα, με τη μορφή συχνά χρησιμοποιούμενων παραδοσιακών υπολογιστικών φύλλων, την παρουσίαση πολυδιάστατων δεδομένων στα οποία είναι πολύπλοκα και όχι διαισθητικά, και λειτουργίες για την αλλαγή των σημείων τομής προβολή των δεδομένων - απαιτούν επίσης χρόνο και περιπλέκουν τη διαδραστική εργασία με δεδομένα.
Ταυτόχρονα, αφενός, οι απαιτήσεις δεδομένων που αφορούν ειδικά συστήματα OLAP συνήθως συνεπάγονται αποθήκευση δεδομένων σε ειδικές δομές βελτιστοποιημένες για τυπικές εργασίες OLAP, αφετέρου, η άμεση εξαγωγή δεδομένων από υπάρχοντα συστήματα κατά τη διαδικασία ανάλυσης θα οδηγούσε σε σημαντική πτώση στην απόδοσή τους.
Ως εκ τούτου, μια σημαντική απαίτηση είναι η παροχή της πιο ευέλικτης σύνδεσης εισαγωγής-εξαγωγής μεταξύ των υπαρχόντων συστημάτων που λειτουργούν ως πηγή δεδομένων και ενός συστήματος OLAP, καθώς και ενός συστήματος OLAP και εξωτερικών εφαρμογών ανάλυσης δεδομένων και αναφοράς.
Επιπλέον, ένας τέτοιος συνδυασμός πρέπει να ικανοποιεί τις προφανείς απαιτήσεις υποστήριξης εισαγωγών-εξαγωγών από διάφορες πηγές δεδομένων, εφαρμογής διαδικασιών καθαρισμού και μετατροπής δεδομένων, ενοποίησης των χρησιμοποιούμενων ταξινομητών και βιβλίων αναφοράς. Επιπλέον, αυτές οι απαιτήσεις συμπληρώνονται από την ανάγκη να ληφθούν υπόψη διάφοροι κύκλοι ενημέρωσης δεδομένων στα υπάρχοντα συστήματα πληροφοριών και να ενοποιηθεί το απαιτούμενο επίπεδο λεπτομέρειας δεδομένων. Η πολυπλοκότητα και η ευελιξία αυτού του προβλήματος οδήγησαν στην εμφάνιση της έννοιας αποθήκες δεδομένωνκαι, με στενή έννοια, στον προσδιορισμό μιας ξεχωριστής κατηγορίας βοηθητικών προγραμμάτων μετατροπής και μετασχηματισμού δεδομένων - ETL (Εξαγωγή φορτίου μετασχηματισμού).
Ενεργά μοντέλα αποθήκευσης δεδομένων
Αναφέραμε παραπάνω ότι το OLAP υποθέτει μια πολυδιάστατη ιεραρχική αναπαράσταση δεδομένων και, κατά μία έννοια, είναι αντίθετη με εκείνες που βασίζονται σε RDBMSσυστήματα.
Αυτό, ωστόσο, δεν σημαίνει ότι όλα τα συστήματα OLAP χρησιμοποιούν ένα πολυδιάστατο μοντέλο για την αποθήκευση ενεργών, «λειτουργικών» δεδομένων συστήματος. Δεδομένου ότι το ενεργό μοντέλο αποθήκευσης δεδομένων επηρεάζει όλες τις απαιτήσεις που υπαγορεύονται από τη δοκιμή FASMI, η σημασία του τονίζεται από το γεγονός ότι σε αυτή τη βάση διακρίνονται παραδοσιακά οι υποτύποι OLAP - πολυδιάστατοι (MOLAP), σχεσικοί (ROLAP) και υβριδικοί (HOLAP).
Ωστόσο, ορισμένοι ειδικοί, με επικεφαλής τους προαναφερθέντες Νάιτζελ Πεντς , υποδεικνύουν ότι η ταξινόμηση με βάση ένα κριτήριο δεν είναι αρκετά πλήρης. Επιπλέον, η συντριπτική πλειοψηφία των υφιστάμενων συστημάτων OLAP θα είναι υβριδικού τύπου. Ως εκ τούτου, θα σταθούμε λεπτομερέστερα στα ενεργά μοντέλα αποθήκευσης δεδομένων, αναφέροντας ποια από αυτά αντιστοιχούν σε ποιους από τους παραδοσιακούς υποτύπους OLAP.
Αποθήκευση ενεργών δεδομένων σε πολυδιάστατη βάση δεδομένων
Σε αυτήν την περίπτωση, τα δεδομένα OLAP αποθηκεύονται σε πολυδιάστατα DBMS, χρησιμοποιώντας σχέδια βελτιστοποιημένα για αυτόν τον τύπο δεδομένων. Συνήθως, τα πολυδιάστατα DBMS υποστηρίζουν όλες τις τυπικές λειτουργίες OLAP, συμπεριλαμβανομένης της συνάθροισης κατά μήκος των απαιτούμενων επιπέδων ιεραρχίας και ούτω καθεξής.
Αυτός ο τύπος αποθήκευσης δεδομένων, κατά μία έννοια, μπορεί να ονομαστεί κλασικός για το OLAP. Ωστόσο, όλα τα βήματα για την προκαταρκτική προετοιμασία δεδομένων είναι απολύτως απαραίτητα για αυτό. Συνήθως, τα πολυδιάστατα δεδομένα DBMS αποθηκεύονται στο δίσκο, ωστόσο, σε ορισμένες περιπτώσεις, για να επιταχυνθεί η επεξεργασία δεδομένων, τέτοια συστήματα επιτρέπουν την αποθήκευση δεδομένων σε μνήμη τυχαίας προσπέλασης. Για τους ίδιους σκοπούς, μερικές φορές χρησιμοποιείται η αποθήκευση προ-υπολογισμένων συγκεντρωτικών τιμών και άλλων υπολογισμένων τιμών στη βάση δεδομένων.
Πολυδιάστατο DBMS, η πλήρης υποστήριξη της πρόσβασης πολλών χρηστών με ανταγωνιστικές συναλλαγές ανάγνωσης και εγγραφής είναι αρκετά σπάνια· η συνήθης λειτουργία για τέτοια DBMS είναι ένας χρήστης με πρόσβαση εγγραφής με πρόσβαση ανάγνωσης πολλών χρηστών ή μόνο για ανάγνωση πολλών χρηστών.
Μεταξύ των αδυναμιών που χαρακτηρίζουν ορισμένες υλοποιήσεις πολυδιάστατων DBMS και συστημάτων OLAP που βασίζονται σε αυτά, μπορεί κανείς να σημειώσει την ευαισθησία τους σε μια απρόβλεπτη αύξηση του χώρου που καταλαμβάνει η βάση δεδομένων από την άποψη του χρήστη. Αυτό το αποτέλεσμα προκαλείται από την επιθυμία να ελαχιστοποιηθεί ο χρόνος αντίδρασης του συστήματος, ο οποίος υπαγορεύει την αποθήκευση προ-υπολογισμένων τιμών αθροιστικών δεικτών και άλλων ποσοτήτων στη βάση δεδομένων, γεγονός που προκαλεί μια μη γραμμική αύξηση του όγκου των πληροφοριών που αποθηκεύονται στη βάση δεδομένων με την προσθήκη νέων τιμών δεδομένων ή μετρήσεων.
Ο βαθμός στον οποίο εκδηλώνεται αυτό το πρόβλημα, καθώς και τα σχετικά προβλήματα της αποτελεσματικής αποθήκευσης αραιών κύβων δεδομένων, καθορίζεται από την ποιότητα των προσεγγίσεων και των αλγορίθμων που χρησιμοποιούνται για συγκεκριμένες υλοποιήσεις συστημάτων OLAP.
Αποθήκευση ενεργών δεδομένων σε μια σχεσιακή βάση δεδομένων
Τα δεδομένα OLAP μπορούν επίσης να αποθηκευτούν στα παραδοσιακά RDBMS. Στις περισσότερες περιπτώσεις, αυτή η προσέγγιση χρησιμοποιείται κατά την προσπάθεια «ανώδυνης» ενσωμάτωσης του OLAP με τα υπάρχοντα λογιστικά συστήματα, είτε με βάση το RDBMS αποθήκες δεδομένων. Ταυτόχρονα, αυτή η προσέγγιση απαιτεί ορισμένες πρόσθετες δυνατότητες από το RDBMS για τη διασφάλιση της αποτελεσματικής εκπλήρωσης των απαιτήσεων της δοκιμής FASMI (ιδίως, διασφαλίζοντας ελάχιστο χρόνο απόκρισης του συστήματος). Συνήθως τα δεδομένα OLAP αποθηκεύονται σε αποκανονικοποιημένοςμορφή, και ορισμένα από τα προυπολογισμένα συγκεντρωτικά στοιχεία και τιμές αποθηκεύονται σε ειδικούς πίνακες. Όταν αποθηκεύεται σε κανονικοποιημένη μορφή, η αποτελεσματικότητα του RDBMS ως μεθόδου αποθήκευσης ενεργών δεδομένων μειώνεται.
Το πρόβλημα της επιλογής αποτελεσματικών προσεγγίσεων και αλγορίθμων για την αποθήκευση προυπολογισμένων δεδομένων είναι επίσης σημαντικό για συστήματα OLAP που βασίζονται σε RDBMS, επομένως οι κατασκευαστές τέτοιων συστημάτων συνήθως εστιάζουν στα πλεονεκτήματα των προσεγγίσεων που χρησιμοποιούνται.
Γενικά, πιστεύεται ότι τα συστήματα OLAP που βασίζονται σε RDBMS είναι πιο αργά από τα συστήματα που βασίζονται σε πολυδιάστατα DBMS, μεταξύ άλλων λόγω των δομών αποθήκευσης δεδομένων που είναι λιγότερο αποτελεσματικές για εργασίες OLAP, αλλά στην πράξη αυτό εξαρτάται από τα χαρακτηριστικά ενός συγκεκριμένου συστήματος.
Μεταξύ των πλεονεκτημάτων της αποθήκευσης δεδομένων σε ένα RDBMS είναι η μεγαλύτερη επεκτασιμότητα τέτοιων συστημάτων.
Αποθήκευση ενεργών δεδομένων σε επίπεδα αρχεία
Αυτή η προσέγγιση περιλαμβάνει την αποθήκευση κομματιών δεδομένων σε κανονικά αρχεία. Συνήθως χρησιμοποιείται ως προσθήκη σε μία από τις δύο κύριες προσεγγίσεις προκειμένου να επιταχυνθεί η εργασία με την προσωρινή αποθήκευση των τρεχόντων δεδομένων στο δίσκο ή στη μνήμη RAM του υπολογιστή-πελάτη.
Υβριδική προσέγγιση στην αποθήκευση δεδομένων
Οι περισσότεροι κατασκευαστές συστημάτων OLAP που προωθούν τις ολοκληρωμένες λύσεις τους, που συχνά περιλαμβάνουν, εκτός από το ίδιο το σύστημα OLAP, DBMS, εργαλεία ETL (Εξαγωγή φορτίου μετασχηματισμού)και την αναφορά, επί του παρόντος χρησιμοποιούν μια υβριδική προσέγγιση για την οργάνωση της αποθήκευσης ενεργών δεδομένων συστήματος, διανέμοντάς τα με τον ένα ή τον άλλο τρόπο μεταξύ ενός RDBMS και μιας εξειδικευμένης αποθήκευσης, καθώς και μεταξύ δομών δίσκου και προσωρινής αποθήκευσης στη μνήμη RAM.
Δεδομένου ότι η αποτελεσματικότητα μιας τέτοιας λύσης εξαρτάται από τις συγκεκριμένες προσεγγίσεις και τους αλγόριθμους που χρησιμοποιούνται από τον κατασκευαστή για να καθορίσει εάν ποια δεδομένα και πού να αποθηκεύσετε, στη συνέχεια βιαστικώς εξάγετε συμπεράσματα σχετικά με την αρχικά μεγαλύτερη αποτελεσματικότητα τέτοιων λύσεων ως κατηγορίας χωρίς να αξιολογήσετε τα ειδικά χαρακτηριστικά του υπό εξέταση συστήματος.
OLAP(eng. on-line analytical processing) – ένα σύνολο μεθόδων για δυναμική επεξεργασία πολυδιάστατων ερωτημάτων σε αναλυτικές βάσεις δεδομένων. Τέτοιες πηγές δεδομένων είναι συνήθως αρκετά μεγάλες σε όγκο και μία από τις πιο σημαντικές απαιτήσεις στα εργαλεία που χρησιμοποιούνται για την επεξεργασία τους είναι η υψηλή ταχύτητα. Στις σχεσιακές βάσεις δεδομένων, οι πληροφορίες αποθηκεύονται σε ξεχωριστούς πίνακες που είναι καλά κανονικοποιημένοι. Αλλά πολύπλοκα ερωτήματα πολλών πινάκων εκτελούνται αρκετά αργά σε αυτά. Σημαντικά καλύτερες επιδόσεις όσον αφορά την ταχύτητα επεξεργασίας στα συστήματα OLAP επιτυγχάνονται λόγω των ιδιαιτεροτήτων της δομής αποθήκευσης δεδομένων. Όλες οι πληροφορίες είναι σαφώς οργανωμένες και χρησιμοποιούνται δύο τύποι αποθήκευσης δεδομένων: Μετρήσεις(περιέχει καταλόγους χωρισμένους σε κατηγορίες, για παράδειγμα, σημεία πώλησης, πελάτες, εργαζόμενους, υπηρεσίες κ.λπ.) και δεδομένα(χαρακτηρίστε την αλληλεπίδραση στοιχείων διαφόρων διαστάσεων, για παράδειγμα, στις 3 Μαρτίου 2010, ο πωλητής Α παρείχε μια υπηρεσία στον πελάτη Β στο κατάστημα Γ για το ποσό των χρηματικών μονάδων D). Τα μέτρα χρησιμοποιούνται για τον υπολογισμό των αποτελεσμάτων στον κύβο ανάλυσης. Τα μέτρα είναι συλλογές γεγονότων που συγκεντρώνονται με αντίστοιχες επιλεγμένες διαστάσεις και τα στοιχεία τους. Χάρη σε αυτά τα χαρακτηριστικά, τα σύνθετα ερωτήματα με πολυδιάστατα δεδομένα χρειάζονται πολύ λιγότερο χρόνο από ό,τι με σχεσιακές πηγές.
Ένας από τους κύριους προμηθευτές συστημάτων OLAP είναι η εταιρεία Microsoft. Ας εξετάσουμε την εφαρμογή των αρχών OLAPσε πρακτικά παραδείγματα δημιουργίας αναλυτικού κύβου σε εφαρμογές Microsoft SQL Server Business Intelligence Development Studio(ΠΡΟΣΦΟΡΕΣ) και Microsoft Office PerformancePoint Server Planning Business Modeler(PPS) και εξοικειωθείτε με τις δυνατότητες οπτικής αναπαράστασης πολυδιάστατων δεδομένων σε μορφή γραφημάτων, διαγραμμάτων και πινάκων.
Για παράδειγμα, στο BIDS είναι απαραίτητο να δημιουργηθεί ένας κύβος OLAP χρησιμοποιώντας δεδομένα σχετικά με μια ασφαλιστική εταιρεία, τους υπαλλήλους της, τους συνεργάτες (πελάτες) και τα σημεία πώλησης. Ας υποθέσουμε ότι η εταιρεία παρέχει έναν τύπο υπηρεσίας, επομένως δεν θα χρειαστεί μέτρηση των υπηρεσιών.
Πρώτα ας ορίσουμε τις μετρήσεις. Οι ακόλουθες οντότητες (κατηγορίες δεδομένων) σχετίζονται με τις δραστηριότητες της εταιρείας:
- Σημεία πώλησης
- Υπαλλήλους
- Συνεργάτες
Στη συνέχεια, χρειάζεστε έναν πίνακα για την αποθήκευση γεγονότων (πίνακας δεδομένων).
Οι πληροφορίες μπορούν να εισαχθούν σε πίνακες με μη αυτόματο τρόπο, αλλά ο πιο συνηθισμένος τρόπος είναι η φόρτωση δεδομένων χρησιμοποιώντας τον Οδηγό εισαγωγής από διάφορες πηγές.
Το παρακάτω σχήμα δείχνει τη ροή της μη αυτόματης δημιουργίας και συμπλήρωσης πινάκων διαστάσεων και γεγονότων:
Εικ.1. Πίνακες διαστάσεων και γεγονότων στην αναλυτική βάση δεδομένων. Ακολουθία δημιουργίας
Αφού δημιουργήσετε μια πολυδιάστατη πηγή δεδομένων στο BIDS, μπορείτε να προβάλετε την παρουσίασή της (Προβολή πηγής δεδομένων). Στο παράδειγμά μας, θα πάρουμε το κύκλωμα που φαίνεται στο παρακάτω σχήμα.
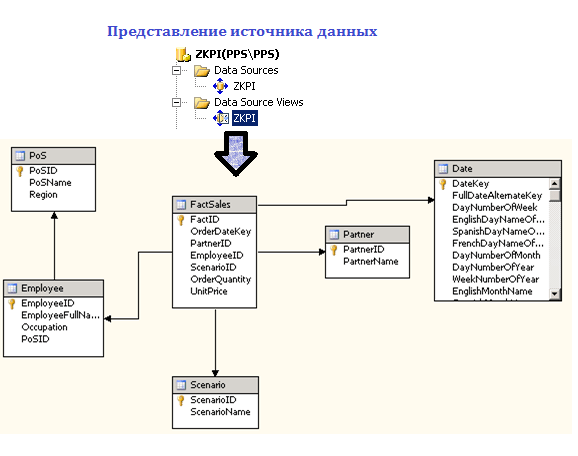
Εικ.2. Προβολή πηγής δεδομένων στο Business Intelligence Development Studio (BIDS)
Όπως μπορείτε να δείτε, ο πίνακας γεγονότων συνδέεται με τους πίνακες διαστάσεων μέσω μιας αντιστοιχίας ενός προς ένα πεδίων αναγνωριστικού (PartnerID, EmployeeID, κ.λπ.).
Ας δούμε το αποτέλεσμα. Στην καρτέλα cube explorer, σύροντας μέτρα και διαστάσεις στα πεδία σύνολα, σειρές, στήλες και φίλτρα, μπορούμε να πάρουμε μια προβολή των δεδομένων που μας ενδιαφέρουν (για παράδειγμα, συναλλαγές σε ασφαλιστήρια συμβόλαια που συνήφθησαν από έναν συγκεκριμένο υπάλληλο το 2005).
Η έννοια της πολυδιάστατης ανάλυσης δεδομένων συνδέεται στενά με τη λειτουργική ανάλυση, η οποία εκτελείται με τη χρήση συστημάτων OLAP.
Το OLAP (On-Line Analytical Processing) είναι μια τεχνολογία για επιχειρησιακή αναλυτική επεξεργασία δεδομένων που χρησιμοποιεί μεθόδους και εργαλεία για τη συλλογή, αποθήκευση και ανάλυση πολυδιάστατων δεδομένων για την υποστήριξη διαδικασιών λήψης αποφάσεων.
Ο κύριος σκοπός των συστημάτων OLAP είναι να υποστηρίζουν αναλυτικές δραστηριότητες και αυθαίρετα (συχνά χρησιμοποιείται ο όρος ad-hoc) αιτήματα από αναλυτές χρηστών. Ο σκοπός της ανάλυσης OLAP είναι να ελέγξει τις αναδυόμενες υποθέσεις.
Η προέλευση της τεχνολογίας OLAP είναι ο ιδρυτής της σχεσιακής προσέγγισης, E. Codd. Το 1993, δημοσίευσε ένα άρθρο με τίτλο «OLAP για αναλυτές χρηστών: Τι πρέπει να είναι». Αυτό το έγγραφο περιγράφει τις βασικές έννοιες των διαδικτυακών αναλυτικών στοιχείων και προσδιορίζει τις ακόλουθες 12 απαιτήσεις που πρέπει να πληρούν τα προϊόντα που επιτρέπουν τη διαδικτυακή ανάλυση. Tokmakov G.P. Βάση δεδομένων. Έννοια βάσης δεδομένων, μοντέλο σχεσιακών δεδομένων, γλώσσες SQL. Σελ. 51
Παρακάτω παρατίθενται οι 12 κανόνες που περιγράφονται από τον Codd που ορίζουν το OLAP.
1. Πολυδιάσταση -- ένα σύστημα OLAP σε εννοιολογικό επίπεδο θα πρέπει να παρουσιάζει δεδομένα με τη μορφή πολυδιάστατου μοντέλου, το οποίο απλοποιεί τις διαδικασίες ανάλυσης και αντίληψης πληροφοριών.
2. Διαφάνεια -- το σύστημα OLAP πρέπει να κρύβει από τον χρήστη την πραγματική υλοποίηση του πολυδιάστατου μοντέλου, τη μέθοδο οργάνωσης, τις πηγές, τα μέσα επεξεργασίας και αποθήκευσης.
3. Διαθεσιμότητα -- Ένα σύστημα OLAP πρέπει να παρέχει στο χρήστη ένα ενιαίο, συνεπές και ολιστικό μοντέλο δεδομένων, παρέχοντας πρόσβαση στα δεδομένα ανεξάρτητα από τον τρόπο ή τον τόπο αποθήκευσης τους.
4. Συνεπής απόδοση κατά την ανάπτυξη αναφορών - η απόδοση των συστημάτων OLAP δεν πρέπει να μειώνεται σημαντικά καθώς αυξάνεται ο αριθμός των διαστάσεων στις οποίες εκτελείται η ανάλυση.
5. Αρχιτεκτονική πελάτη-διακομιστή -- το σύστημα OLAP πρέπει να μπορεί να λειτουργεί σε περιβάλλον πελάτη-διακομιστή, επειδή Τα περισσότερα από τα δεδομένα που σήμερα πρέπει να υποβληθούν σε επιχειρησιακή αναλυτική επεξεργασία αποθηκεύονται κατανεμημένα. Η κύρια ιδέα εδώ είναι ότι το στοιχείο διακομιστή του εργαλείου OLAP θα πρέπει να είναι αρκετά έξυπνο και να επιτρέπει την κατασκευή ενός κοινού εννοιολογικού σχήματος βασισμένου στη γενίκευση και ενοποίηση διαφόρων λογικών και φυσικών σχημάτων εταιρικών βάσεων δεδομένων για να παρέχει το αποτέλεσμα της διαφάνειας.
6. Ισότητα διαστάσεων -- Το σύστημα OLAP πρέπει να υποστηρίζει ένα πολυδιάστατο μοντέλο στο οποίο όλες οι διαστάσεις είναι ίσες. Εάν είναι απαραίτητο, μπορούν να παρέχονται πρόσθετα χαρακτηριστικά σε μεμονωμένες διαστάσεις, αλλά αυτή η δυνατότητα πρέπει να παρέχεται σε οποιαδήποτε διάσταση.
7. Δυναμική διαχείριση αραιών πινάκων -- το σύστημα OLAP πρέπει να παρέχει τη βέλτιστη επεξεργασία των αραιών πινάκων. Η ταχύτητα πρόσβασης πρέπει να διατηρείται ανεξάρτητα από τη θέση των κελιών δεδομένων και να είναι σταθερή για μοντέλα με διαφορετικούς αριθμούς διαστάσεων και διαφορετικούς βαθμούς αραιότητας δεδομένων.
8. Υποστήριξη για λειτουργία πολλών χρηστών - το σύστημα OLAP πρέπει να παρέχει τη δυνατότητα σε πολλούς χρήστες να συνεργάζονται με ένα αναλυτικό μοντέλο ή να δημιουργούν διαφορετικά μοντέλα για αυτούς από μεμονωμένα δεδομένα. Σε αυτή την περίπτωση, είναι δυνατή τόσο η ανάγνωση όσο και η εγγραφή δεδομένων, επομένως το σύστημα πρέπει να διασφαλίζει την ακεραιότητα και την ασφάλειά τους.
9. Απεριόριστες διασταυρούμενες λειτουργίες -- το σύστημα OLAP πρέπει να διασφαλίζει ότι οι λειτουργικές σχέσεις που περιγράφονται χρησιμοποιώντας μια συγκεκριμένη επίσημη γλώσσα μεταξύ των κελιών του υπερκύβου διατηρούνται κατά την εκτέλεση οποιωνδήποτε λειτουργιών κοπής, περιστροφής, ενοποίησης ή διάτρησης. Το σύστημα θα πρέπει να πραγματοποιεί ανεξάρτητα (αυτόματα) τον μετασχηματισμό των καθιερωμένων σχέσεων, χωρίς να απαιτεί από τον χρήστη να τις επαναπροσδιορίσει.
10. Διαισθητικός χειρισμός δεδομένων -- Ένα σύστημα OLAP πρέπει να παρέχει έναν τρόπο εκτέλεσης εργασιών τεμαχισμού, περιστροφής, ενοποίησης και διάτρησης σε έναν υπερκύβο χωρίς ο χρήστης να χρειάζεται να κάνει πολλούς χειρισμούς διεπαφής. Οι διαστάσεις που ορίζονται στο αναλυτικό μοντέλο πρέπει να περιέχουν όλες τις απαραίτητες πληροφορίες για την εκτέλεση των παραπάνω πράξεων.
11. Ευέλικτες επιλογές για τη λήψη αναφορών -- το σύστημα OLAP πρέπει να υποστηρίζει διάφορες μεθόδους οπτικοποίησης δεδομένων, π.χ. Οι εκθέσεις θα πρέπει να παρουσιάζονται με οποιονδήποτε πιθανό προσανατολισμό. Τα εργαλεία αναφοράς πρέπει να παρουσιάζουν συνθετικά δεδομένα ή πληροφορίες που προκύπτουν από το μοντέλο δεδομένων με οποιονδήποτε πιθανό προσανατολισμό. Αυτό σημαίνει ότι οι γραμμές, οι στήλες ή οι σελίδες πρέπει να εμφανίζουν από 0 έως N διαστάσεις κάθε φορά, όπου N είναι ο αριθμός των διαστάσεων ολόκληρου του αναλυτικού μοντέλου. Επιπλέον, κάθε ιδιότητα περιεχομένου που εμφανίζεται σε μία ανάρτηση, στήλη ή σελίδα πρέπει να επιτρέπει σε οποιοδήποτε υποσύνολο των στοιχείων (τιμών) που περιέχονται στην ιδιότητα να εμφανίζονται με οποιαδήποτε σειρά.
12. Απεριόριστη διάσταση και αριθμός επιπέδων συγκέντρωσης - έρευνα σχετικά με τον πιθανό αριθμό απαραίτητων διαστάσεων που απαιτούνται στο αναλυτικό μοντέλο έδειξε ότι μπορούν να χρησιμοποιηθούν ταυτόχρονα έως και 19 διαστάσεις. Ως εκ τούτου, συνιστάται έντονα το αναλυτικό εργαλείο να μπορεί να παρέχει τουλάχιστον 15, και κατά προτίμηση 20, μετρήσεις ταυτόχρονα. Επιπλέον, καθεμία από τις κοινές διαστάσεις δεν πρέπει να περιορίζεται στον αριθμό των επιπέδων συγκέντρωσης και των διαδρομών ενοποίησης που καθορίζονται από τον αναλυτή.
Πρόσθετοι κανόνες του Codd.
Το σύνολο αυτών των απαιτήσεων, το οποίο χρησίμευσε ως ο de facto ορισμός του OLAP, προκαλεί αρκετά συχνά διάφορα παράπονα, για παράδειγμα, οι κανόνες 1, 2, 3, 6 είναι απαιτήσεις και οι κανόνες 10, 11 είναι ανεπίσημες επιθυμίες. Tokmakov G.P. Βάση δεδομένων. Έννοια βάσης δεδομένων, μοντέλο σχεσιακών δεδομένων, γλώσσες SQL. Σελ. 68 Έτσι, οι 12 απαιτήσεις του Codd που απαριθμούνται δεν μας επιτρέπουν να ορίσουμε με ακρίβεια το OLAP. Το 1995, ο Codd πρόσθεσε τους ακόλουθους έξι κανόνες στην παραπάνω λίστα:
13. Ανάκτηση παρτίδας έναντι ερμηνείας -- Ένα σύστημα OLAP πρέπει να παρέχει πρόσβαση τόσο στα δικά του όσο και στα εξωτερικά δεδομένα εξίσου αποτελεσματικά.
14. Υποστήριξη για όλα τα μοντέλα ανάλυσης OLAP -- Ένα σύστημα OLAP πρέπει να υποστηρίζει και τα τέσσερα μοντέλα ανάλυσης δεδομένων που ορίζονται από τον Codd: κατηγορηματικά, ερμηνευτικά, εικαστικά και στερεότυπα.
15. Επεξεργασία μη κανονικοποιημένων δεδομένων -- το σύστημα OLAP πρέπει να είναι ενσωματωμένο με μη κανονικοποιημένες πηγές δεδομένων. Οι τροποποιήσεις δεδομένων που γίνονται στο περιβάλλον OLAP δεν θα πρέπει να έχουν ως αποτέλεσμα αλλαγές στα δεδομένα που είναι αποθηκευμένα στα αρχικά εξωτερικά συστήματα.
16. Αποθήκευση αποτελεσμάτων OLAP: αποθήκευση τους χωριστά από τα δεδομένα προέλευσης - ένα σύστημα OLAP που λειτουργεί σε λειτουργία ανάγνωσης-εγγραφής πρέπει να αποθηκεύει τα αποτελέσματα ξεχωριστά μετά την τροποποίηση των δεδομένων προέλευσης. Με άλλα λόγια, διασφαλίζεται η ασφάλεια των αρχικών δεδομένων.
17. Εξάλειψη των τιμών που λείπουν - Ένα σύστημα OLAP, όταν παρουσιάζει δεδομένα στον χρήστη, πρέπει να απορρίψει όλες τις τιμές που λείπουν. Με άλλα λόγια, οι τιμές που λείπουν πρέπει να είναι διαφορετικές από τις μηδενικές τιμές.
18. Χειρισμός τιμών που λείπουν -- Το σύστημα OLAP πρέπει να αγνοεί όλες τις τιμές που λείπουν, ανεξάρτητα από την πηγή τους. Αυτό το χαρακτηριστικό σχετίζεται με τον 17ο κανόνα.
Επιπλέον, ο Codd χώρισε και τους 18 κανόνες στις ακόλουθες τέσσερις ομάδες, αποκαλώντας τους χαρακτηριστικά. Αυτές οι ομάδες ονομάστηκαν B, S, R και D.
Τα κύρια χαρακτηριστικά του (Β) περιλαμβάνουν τους ακόλουθους κανόνες:
Πολυδιάστατη εννοιολογική αναπαράσταση δεδομένων (κανόνας 1).
Διαισθητικός χειρισμός δεδομένων (κανόνας 10).
Διαθεσιμότητα (κανόνας 3).
Εξαγωγή παρτίδας έναντι ερμηνείας (κανόνας 13).
Υποστήριξη για όλα τα μοντέλα ανάλυσης OLAP (κανόνας 14).
Αρχιτεκτονική πελάτη-διακομιστή (κανόνας 5).
Διαφάνεια (κανόνας 2).
Υποστήριξη πολλών χρηστών (κανόνας 8)
Ειδικά Χαρακτηριστικά (S):
Επεξεργασία μη κανονικοποιημένων δεδομένων (κανόνας 15).
Αποθήκευση αποτελεσμάτων OLAP: αποθήκευση τους χωριστά από τα δεδομένα προέλευσης (κανόνας 16).
Εξάλειψη των τιμών που λείπουν (κανόνας 17).
Χειρισμός τιμών που λείπουν (κανόνας 18). Λειτουργίες αναφοράς (R):
Ευελιξία στην υποβολή εκθέσεων (κανόνας 11).
Τυπική απόδοση αναφοράς (κανόνας 4).
Αυτόματη διαμόρφωση φυσικού επιπέδου (τροποποιημένος αρχικός κανόνας 7).
Έλεγχος διαστάσεων (D):
Καθολικότητα των μετρήσεων (κανόνας 6).
Απεριόριστος αριθμός διαστάσεων και επιπέδων συγκέντρωσης (κανόνας 12).
Απεριόριστες λειτουργίες μεταξύ των διαστάσεων (κανόνας 9).