Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Posted on http://www.allbest.ru/
Course work
discipline: Databases
Subject: TechnologyOLAP
Completed:
Chizhikov Alexander Alexandrovich
Introduction
1. Classification of OLAP products
2. OLAP client - OLAP server: pros and cons
3. Core OLAP system
3.1 Design principles
Conclusion
List of sources used
Applications
INconducting
It is difficult to find a person in the computer world who, at least on an intuitive level, does not understand what databases are and why they are needed. Unlike traditional relational DBMSs, the concept of OLAP is not so widely known, although almost everyone has probably heard the mysterious term “OLAP cubes”. What is OnLine Analytical Processing?
OLAP is not a separate software product, not a programming language, or even a specific technology. If we try to cover OLAP in all its manifestations, then it is a set of concepts, principles and requirements that underlie software products that make it easier for analysts to access data. Although no one would disagree with such a definition, it is doubtful that it would bring non-specialists one iota closer to understanding the subject. Therefore, in your quest to understand OLAP, it is better to take a different path. First, we need to find out why analysts need to somehow specifically facilitate access to data.
The fact is that analysts are special consumers of corporate information. The analyst's task is to find patterns in large amounts of data. Therefore, the analyst will not pay attention to a single fact; he needs information about hundreds and thousands of events. By the way, one of the significant points that led to the emergence of OLAP is productivity and efficiency. Let's imagine what happens when an analyst needs to obtain information, but there are no OLAP tools in the enterprise. The analyst independently (which is unlikely) or with the help of a programmer makes the appropriate SQL query and receives the data of interest in the form of a report or exports it to a spreadsheet. A great many problems arise in this case. Firstly, the analyst is forced to do something other than his job (SQL programming) or wait for programmers to complete the task for him - all this negatively affects labor productivity, the rate of heart attack and stroke increases, and so on. Secondly, a single report or table, as a rule, does not save the giants of thought and the fathers of Russian analysis - and the whole procedure will have to be repeated again and again. Thirdly, as we have already found out, analysts do not ask about trifles - they need everything at once. This means (although technology is advancing by leaps and bounds) that the corporate relational DBMS server accessed by the analyst can think deeply and for a long time, blocking other transactions.
The concept of OLAP appeared precisely to solve such problems. OLAP cubes are essentially meta reports. By cutting meta-reports (cubes, that is) along dimensions, the analyst actually receives the “ordinary” two-dimensional reports that interest him (these are not necessarily reports in the usual sense of the term - we are talking about data structures with the same functions). The advantages of cubes are obvious - data needs to be requested from a relational DBMS only once - when building a cube. Since analysts, as a rule, do not work with information that is supplemented and changed on the fly, the generated cube is relevant for quite a long time. Thanks to this, not only are interruptions in the operation of the relational DBMS server eliminated (there are no queries with thousands and millions of response lines), but the speed of access to data for the analyst himself also sharply increases. In addition, as already noted, performance is also improved by calculating subsums of hierarchies and other aggregated values at the time the cube is built.
Of course, you have to pay to increase productivity in this way. It is sometimes said that the data structure simply “explodes” - an OLAP cube can take up tens or even hundreds of times more space than the original data.
Now that we have a little understanding of how OLAP works and what it serves, it is still worth formalizing our knowledge somewhat and giving OLAP criteria without simultaneous translation into ordinary human language. These criteria (12 in total) were formulated in 1993 by E.F. Codd - the creator of the concept of relational DBMS and, concurrently, OLAP. We will not consider them directly, since they were later reworked into the so-called FASMI test, which determines the requirements for OLAP products. FASMI is an acronym for the name of each test item:
Fast (fast). This property means that the system must provide a response to a user request in an average of five seconds; however, most requests are processed within one second, and the most complex requests should be processed within twenty seconds. Recent studies have shown that the user begins to doubt the success of a request if it takes more than thirty seconds.
Analysis (analytical). The system must be able to handle any logical and statistical analysis typical of business applications, and ensure that the results are stored in a form accessible to the end user. Analysis tools may include procedures for analyzing time series, cost distribution, currency conversion, modeling changes in organizational structures, and some others.
Shared. The system should provide ample opportunities for restricting access to data and simultaneous operation of many users.
Multidimensional (multidimensional). The system must provide a conceptually multidimensional view of data, including full support for multiple hierarchies.
Information. The power of various software products is characterized by the amount of input data processed. Different OLAP systems have different capacities: advanced OLAP solutions can handle at least a thousand times more data than the least powerful ones. When choosing an OLAP tool, there are a number of factors to consider, including data duplication, memory requirements, disk space usage, performance metrics, integration with information warehouses, and so on.
1. Classification of OLAP products
So, the essence of OLAP is that the information source for analysis is presented in the form of a multidimensional cube, and it is possible to arbitrarily manipulate it and obtain the necessary information sections - reports. In this case, the end user sees the cube as a multidimensional dynamic table that automatically summarizes data (facts) in various sections (dimensions), and allows interactive management of calculations and report form. These operations are performed by the OLAP engine (or OLAP calculation engine).
Today, many products have been developed around the world that implement OLAP technologies. To make it easier to navigate among them, classifications of OLAP products are used: by the method of storing data for analysis and by the location of the OLAP machine. Let's take a closer look at each category of OLAP products.
I'll start with a classification based on the method of data storage. Let me remind you that multidimensional cubes are built on the basis of source and aggregate data. Both source and aggregate data for cubes can be stored in both relational and multidimensional databases. Therefore, three methods of data storage are currently used: MOLAP (Multidimensional OLAP), ROLAP (Relational OLAP) and HOLAP (Hybrid OLAP). Accordingly, OLAP products are divided into three similar categories based on the method of data storage:
1.In the case of MOLAP, source and aggregate data are stored in a multidimensional database or in a multidimensional local cube.
2.In ROLAP products, source data is stored in relational databases or in flat local tables on a file server. Aggregate data can be placed in service tables in the same database. Conversion of data from a relational database into multidimensional cubes occurs at the request of an OLAP tool.
3. When using HOLAP architecture, the source data remains in the relational database, and the aggregates are placed in the multidimensional one. An OLAP cube is built at the request of an OLAP tool based on relational and multidimensional data.
The next classification is based on the location of the OLAP machine. Based on this feature, OLAP products are divided into OLAP servers and OLAP clients:
In server OLAP tools, calculations and storage of aggregate data are performed by a separate process - the server. The client application receives only the results of queries against multidimensional cubes that are stored on the server. Some OLAP servers support data storage only in relational databases, some only in multidimensional ones. Many modern OLAP servers support all three data storage methods: MOLAP, ROLAP and HOLAP.
The OLAP client is designed differently. The construction of a multidimensional cube and OLAP calculations are performed in the memory of the client computer. OLAP clients are also divided into ROLAP and MOLAP. And some may support both data access options.
Each of these approaches has its own pros and cons. Contrary to popular belief about the advantages of server tools over client tools, in a number of cases, using an OLAP client for users can be more effective and profitable than using an OLAP server.
2. OLAP client - OLAP server: pros and cons
When building an information system, OLAP functionality can be implemented using both server and client OLAP tools. In practice, the choice is a trade-off between performance and software cost.
The volume of data is determined by the combination of the following characteristics: number of records, number of dimensions, number of dimension elements, length of dimensions and number of facts. It is known that an OLAP server can process larger volumes of data than an OLAP client with equal computer power. This is because the OLAP server stores a multidimensional database containing precomputed cubes on hard drives.
When performing OLAP operations, client programs execute queries on it in an SQL-like language, receiving not the entire cube, but its displayed fragments. The OLAP client must have the entire cube in RAM at the time of operation. In the case of a ROLAP architecture, it is necessary to first load into memory the entire data array used to calculate the cube. Additionally, as the number of dimensions, facts, or dimension members increases, the number of aggregates grows exponentially. Thus, the amount of data processed by the OLAP client is directly dependent on the amount of RAM on the user's PC.
However, note that most OLAP clients provide distributed computing. Therefore, the number of processed records, which limits the work of the client OLAP tool, is understood not as the volume of primary data in the corporate database, but as the size of the aggregated sample from it. The OLAP client generates a request to the DBMS, which describes the filtering conditions and the algorithm for preliminary grouping of the primary data. The server finds, groups records and returns a compact selection for further OLAP calculations. The size of this sample can be tens or hundreds of times smaller than the volume of primary, non-aggregated records. Consequently, the need for such an OLAP client in PC resources is significantly reduced.
In addition, the number of dimensions is subject to limitations in human perception. It is known that the average person can simultaneously operate with 3-4, maximum 8 dimensions. With a larger number of dimensions in a dynamic table, the perception of information becomes significantly more difficult. This factor should be taken into account when preliminary calculating the RAM that may be required by the OLAP client.
The length of the dimensions also affects the size of the OLAP engine's address space when computing an OLAP cube. The longer the dimensions, the more resources are required to presort a multidimensional array, and vice versa. Only short measurements in the source data is another argument in favor of the OLAP client.
This characteristic is determined by the two factors discussed above: the volume of data processed and the power of computers. As the number, for example, of dimensions increases, the performance of all OLAP tools decreases due to a significant increase in the number of aggregates, but the rate of decrease is different. Let's demonstrate this dependence on a graph.
Scheme 1. Dependence of the performance of client and server OLAP tools on an increase in data volume
The speed characteristics of an OLAP server are less sensitive to data growth. This is explained by different technologies for processing user requests by the OLAP server and OLAP client. For example, during a drill-down operation, the OLAP server accesses the stored data and “pulls” the data from this “branch”. The OLAP client calculates the entire set of aggregates at the time of loading. However, up to a certain amount of data, the performance of server and client tools is comparable. For OLAP clients that support distributed computing, the scope of performance comparability can extend to data volumes that cover the OLAP analysis needs of a huge number of users. This is confirmed by the results of internal testing of MS OLAP Server and the OLAP client "Kontur Standard". The test was performed on an IBM PC Pentium Celeron 400 MHz, 256 Mb for a sample of 1 million unique (ie, aggregated) records with 7 dimensions containing from 10 to 70 members. The cube loading time in both cases does not exceed 1 second, and various OLAP operations (drill up, drill down, move, filter, etc.) are completed in hundredths of a second.
When the sample size exceeds the amount of RAM, swapping with the disk begins and the performance of the OLAP client drops sharply. Only from this moment can we talk about the advantage of the OLAP server.
It should be remembered that the “breaking point” determines the limit of a sharp increase in the cost of an OLAP solution. For the tasks of each specific user, this point is easily determined by performance tests of the OLAP client. Such tests can be obtained from the development company.
In addition, the cost of a server OLAP solution increases as the number of users increases. The fact is that the OLAP server performs calculations for all users on one computer. Accordingly, the greater the number of users, the more RAM and processing power. Thus, if the volumes of data being processed are in the area of comparable performance of server and client systems, then, other things being equal, using an OLAP client will be more profitable.
Using an OLAP server in the “classical” ideology involves uploading relational DBMS data into a multidimensional database. The upload is performed over a certain period, so the OLAP server data does not reflect the current state. Only those OLAP servers that support the ROLAP mode of operation are free from this drawback.
Similarly, a number of OLAP clients allow you to implement ROLAP and Desktop architectures with direct access to the database. This ensures on-line analysis of source data.
The OLAP server places minimal requirements on the power of client terminals. Objectively, the requirements of an OLAP client are higher, because... it performs calculations in the user's PC RAM. The state of a particular organization's hardware fleet is the most important indicator that must be taken into account when choosing an OLAP tool. But there are also “pros” and “cons” here. An OLAP server does not use the enormous computing power of modern personal computers. If an organization already has a fleet of modern PCs, it is ineffective to use them only as display terminals and at the same time incur additional costs for the central server.
If the power of the users' computers "leaves much to be desired," the OLAP client will work slowly or not be able to work at all. Buying one powerful server may be cheaper than upgrading all your PCs.
Here it is useful to take into account trends in hardware development. Since the volume of data for analysis is practically constant, a steady increase in PC power will lead to an expansion of the capabilities of OLAP clients and their displacement of OLAP servers into the segment of very large databases.
When using an OLAP server over the network, only the data to be displayed is transferred to the client's PC, while the OLAP client receives the entire volume of primary data.
Therefore, where an OLAP client is used, network traffic will be higher.
But, when using an OLAP server, user operations, for example, detailing, generate new queries to the multidimensional database, and, therefore, new data transfer. The execution of OLAP operations by an OLAP client is performed in RAM and, accordingly, does not cause new data flows in the network.
It should also be noted that modern network hardware provides high levels of throughput.
Therefore, in the vast majority of cases, analyzing a “medium” sized database using an OLAP client will not slow down the user’s work.
The cost of an OLAP server is quite high. This should also include the cost of a dedicated computer and the ongoing costs of administering a multidimensional database. In addition, the implementation and maintenance of an OLAP server requires fairly highly qualified personnel.
The cost of an OLAP client is an order of magnitude lower than the cost of an OLAP server. No administration or additional technical equipment is required for the server. There are no high requirements for personnel qualifications when implementing an OLAP client. An OLAP client can be implemented much faster than an OLAP server.
Development of analytical applications using client OLAP tools is a fast process and does not require special training. A user who knows the physical implementation of the database can develop an analytical application independently, without the involvement of an IT specialist. When using an OLAP server, you need to learn 2 different systems, sometimes from different vendors - to create cubes on the server, and to develop a client application. The OLAP client provides a single visual interface for describing cubes and setting up user interfaces for them.
Let's walk through the process of creating an OLAP application using the client tool.
Diagram 2. Creating an OLAP application using a ROLAP client tool
The operating principle of ROLAP clients is a preliminary description of the semantic layer, behind which the physical structure of the source data is hidden. In this case, data sources can be: local tables, RDBMS. The list of supported data sources is determined by the specific software product. After this, the user can independently manipulate objects that he understands in terms of the subject area to create cubes and analytical interfaces.
The operating principle of the OLAP server client is different. In an OLAP server, when creating cubes, the user manipulates the physical descriptions of the database.
At the same time, custom descriptions are created in the cube itself. The OLAP server client is configured only for the cube.
Let us explain the principle of operation of the ROLAP client using the example of creating a dynamic sales report (see Diagram 2). Let the initial data for analysis be stored in two tables: Sales and Deal.
When creating a semantic layer, data sources - the Sales and Deal tables - are described in terms that the end user can understand and turn into “Products” and “Deals”. The "ID" field from the "Products" table is renamed to "Code", and the "Name" to "Product", etc.
Then the Sales business object is created. A business object is a flat table on the basis of which a multidimensional cube is formed. When creating a business object, the "Products" and "Transactions" tables are merged by the "Code" field of the product. Since all table fields are not required for display in the report, the business object uses only the “Item”, “Date” and “Amount” fields.
Next, an OLAP report is created based on the business object. The user selects a business object and drags its attributes onto the column or row areas of the report table. In our example, based on the “Sales” business object, a report on product sales by month was created.
When working with an interactive report, the user can set filtering and grouping conditions with the same simple mouse movements. At this point, the ROLAP client accesses the data in the cache. The OLAP server client generates a new query to the multidimensional database. For example, by applying a filter by product in a sales report, you can get a report on sales of products that interest us.
All OLAP application settings can be stored in a dedicated metadata repository, in the application, or in a multidimensional database system repository. Implementation depends on the specific software product.
So, in what cases can using an OLAP client be more effective and profitable for users than using an OLAP server?
The economic feasibility of using an OLAP server arises when the volumes of data are very large and overwhelming for the OLAP client, otherwise the use of the latter is more justified. In this case, the OLAP client combines high performance characteristics and low cost.
Powerful PCs for analysts are another argument in favor of OLAP clients. When using an OLAP server, these capacities are not used. Among the advantages of OLAP clients are the following:
The costs of implementing and maintaining an OLAP client are significantly lower than the costs of an OLAP server.
When using an OLAP client with an embedded machine, data is transferred over the network once. When performing OLAP operations, no new data streams are generated.
Setting up ROLAP clients is simplified by eliminating the intermediate step - creating a multidimensional database.
3. Core OLAP system
3.1 Design principles
application client core data
From what has already been said, it is clear that the OLAP mechanism is one of the popular methods of data analysis today. There are two main approaches to solving this problem. The first of them is called Multidimensional OLAP (MOLAP) - implementation of the mechanism using a multidimensional database on the server side, and the second Relational OLAP (ROLAP) - building cubes on the fly based on SQL queries to a relational DBMS. Each of these approaches has its pros and cons. Their comparative analysis is beyond the scope of this work. Only the core implementation of the desktop ROLAP module will be described here.
This task arose after using a ROLAP system built on the basis of Decision Cube components included in Borland Delphi. Unfortunately, the use of this set of components showed poor performance on large amounts of data. This problem can be mitigated by trying to cut out as much data as possible before feeding it into cubes. But this is not always enough.
You can find a lot of information about OLAP systems on the Internet and in the press, but almost nowhere is it said about how it works inside.
Scheme of work:
The general scheme of operation of a desktop OLAP system can be represented as follows:
Diagram 3. Operation of a desktop OLAP system
The operating algorithm is as follows:
1. Obtaining data in the form of a flat table or the result of executing an SQL query.
2.Caching data and converting it to a multidimensional cube.
3.Displaying the constructed cube using a cross-tab or chart, etc. In general, an arbitrary number of views can be connected to one cube.
Let's consider how such a system can be arranged internally. We will start from the side that can be seen and touched, that is, from the displays. The displays used in OLAP systems most often come in two types - cross-tabs and charts. Let's look at a crosstab, which is the basic and most common way to display a cube.
In the figure below, rows and columns containing aggregated results are shown in yellow, cells containing facts are in light gray, and cells containing dimensional data are in dark gray.
Thus, the table can be divided into the following elements, which we will work with in the future:
When filling out the matrix with facts, we must proceed as follows:
Based on the measurement data, determine the coordinates of the element to be added in the matrix.
Determine the coordinates of the columns and rows of the totals that are affected by the added element.
Add an element to the matrix and the corresponding total columns and rows.
It should be noted that the resulting matrix will be very sparse, which is why its organization in the form of a two-dimensional array (the option lying on the surface) is not only irrational, but, most likely, impossible due to the large dimension of this matrix, for storing which there is no No amount of RAM is enough. For example, if our cube contains information about sales for one year, and if it has only 3 dimensions - Customers (250), Products (500) and Date (365), then we will get a fact matrix of the following dimensions: number of elements = 250 x 500 x 365 = 45,625,000. And this despite the fact that there may be only a few thousand filled elements in the matrix. Moreover, the greater the number of dimensions, the more sparse the matrix will be.
Therefore, to work with this matrix, you need to use special mechanisms for working with sparse matrices. Various options for organizing a sparse matrix are possible. They are quite well described in the programming literature, for example, in the first volume of the classic book "The Art of Programming" by Donald Knuth.
Let us now consider how we can determine the coordinates of a fact, knowing the dimensions corresponding to it. To do this, let's take a closer look at the header structure:
In this case, you can easily find a way to determine the numbers of the corresponding cell and the totals in which it falls. Several approaches can be proposed here. One is to use a tree to find matching cells. This tree can be constructed by traversing the selection. In addition, an analytical recurrence formula can be easily defined to calculate the required coordinate.
The data stored in the table needs to be transformed in order to be used. Thus, in order to improve performance when building a hypercube, it is desirable to find unique elements stored in columns that are dimensions of the cube. In addition, you can perform preliminary aggregation of facts for records that have the same dimension values. As mentioned above, the unique values available in the measurement fields are important to us. Then the following structure can be proposed for storing them:
Scheme 4. Structure for storing unique values
By using this structure, we significantly reduce the memory requirement. Which is quite relevant, because... To increase operating speed, it is advisable to store data in RAM. In addition, you can only store an array of elements, and dump their values to disk, since we will only need them when displaying the cross-tab.
The ideas described above were the basis for creating the CubeBase component library.
Diagram 5. Structure of the CubeBase component library
TСubeSource performs caching and conversion of data into an internal format, as well as preliminary aggregation of data. The TCubeEngine component performs hypercube calculations and operations with it. In fact, it is an OLAP engine that transforms a flat table into a multidimensional data set. The TCubeGrid component displays the crosstab and controls the display of the hypercube. TСubeChart allows you to see the hypercube in the form of graphs, and the TСubePivote component controls the operation of the cube core.
So, I looked at the architecture and interaction of components that can be used to build an OLAP machine. Now let's take a closer look at the internal structure of the components.
The first stage of the system will be loading data and converting it into an internal format. A logical question would be: why is this necessary, since you can simply use data from a flat table, viewing it when constructing a cube slice. In order to answer this question, let's look at the table structure from the point of view of an OLAP machine. For OLAP systems, table columns can be either facts or dimensions. However, the logic for working with these columns will be different. In a hypercube, the dimensions are actually the axes, and the dimension values are the coordinates on those axes. In this case, the cube will be filled very unevenly - there will be combinations of coordinates that will not correspond to any records and there will be combinations that correspond to several records in the original table, and the first situation is more common, that is, the cube will be similar to the universe - empty space, in some places which there are clusters of points (facts). Thus, if we perform data preaggregation during the initial data loading, that is, we combine records that have the same measurement values, while calculating preliminary aggregated fact values, then in the future we will have to work with fewer records, which will increase the speed of work and reduce requirements to the amount of RAM.
To build slices of a hypercube, we need the following capabilities - defining coordinates (actually measurement values) for table records, as well as defining records that have specific coordinates (measurement values). Let's consider how these possibilities can be realized. The easiest way to store a hypercube is to use a database of its own internal format.
Schematically, the transformations can be represented as follows:
Figure 6: Converting an Internal Format Database to a Normalized Database
That is, instead of one table, we got a normalized database. In fact, normalization reduces the speed of the system, database specialists may say, and in this they will certainly be right, in the case when we need to get values for dictionary elements (in our case, measurement values). But the thing is that we don’t need these values at all at the stage of constructing the slice. As mentioned above, we are only interested in the coordinates in our hypercube, so we will define the coordinates for the measurement values. The easiest thing to do would be to renumber the element values. In order for the numbering to be unambiguous within one dimension, we first sort the lists of dimension values (dictionaries, in database terms) in alphabetical order. In addition, we will renumber the facts, and the facts are pre-aggregated. We get the following diagram:
Scheme 7. Renumbering the normalized database to determine the coordinates of measurement values
Now all that remains is to connect the elements of different tables with each other. In the theory of relational databases, this is done using special intermediate tables. It is enough for us to associate each entry in the measurement tables with a list, the elements of which will be the numbers of facts in the formation of which these measurements were used (that is, to determine all facts that have the same value of the coordinate described by this measurement). For facts, each record will be matched to the values of the coordinates along which it is located in the hypercube. In the future, the coordinates of a record in a hypercube will be understood as the numbers of the corresponding records in the tables of measurement values. Then for our hypothetical example we get the following set defining the internal representation of the hypercube:
Diagram 8. Internal representation of a hypercube
This will be our internal representation of the hypercube. Since we are not making it for a relational database, we simply use fields of variable length as fields for connecting measurement values (we would not be able to do this in an RDB, since the number of table columns is predetermined there).
We could try to use a set of temporary tables to implement the hypercube, but this method will provide too low performance (for example, a set of Decision Cube components), so we will use our own data storage structures.
To implement a hypercube, we need to use data structures that will ensure maximum performance and minimal RAM consumption. Obviously, our main structures will be for storing dictionaries and fact tables. Let's look at the tasks that a dictionary must perform at maximum speed:
checking the presence of an element in the dictionary;
adding an element to the dictionary;
search for record numbers that have a specific coordinate value;
search for coordinates by measurement value;
searching for a measurement value by its coordinate.
Various data types and structures can be used to implement these requirements. For example, you can use arrays of structures. In a real case, these arrays require additional indexing mechanisms that will increase the speed of loading data and retrieving information.
To optimize the operation of a hypercube, it is necessary to determine which tasks need to be solved as a matter of priority, and by what criteria we need to improve the quality of work. The main thing for us is to increase the speed of the program, while it is desirable that a not very large amount of RAM is required. Increased performance is possible through the introduction of additional mechanisms for accessing data, for example, the introduction of indexing. Unfortunately, this increases the RAM overhead. Therefore, we will determine which operations we need to perform at the highest speed. To do this, consider the individual components that implement the hypercube. These components have two main types - dimension and fact table. For measurement, a typical task would be:
adding a new value;
determining the coordinate based on the measurement value;
determination of value by coordinate.
When adding a new element value, we need to check whether we already have such a value, and if so, then do not add a new one, but use the existing coordinate, otherwise we need to add a new element and determine its coordinate. To do this, you need a way to quickly find the presence of the desired element (in addition, such a problem arises when determining the coordinate by the value of the element). For this purpose, it is optimal to use hashing. In this case, the optimal structure would be to use hash trees in which we will store references to elements. In this case, the elements will be the lines of the dimension dictionary. Then the structure of the measurement value can be represented as follows:
PFactLink = ^TFactLink;
TFactLink = record
FactNo: integer; // fact index in the table
TDimensionRecord = record
Value: string; // measurement value
Index: integer; // coordinate value
FactLink: PFactLink; // pointer to the beginning of the list of fact table elements
And in the hash tree we will store links to unique elements. In addition, we need to solve the problem of inverse transformation - using the coordinate to determine the measurement value. To ensure maximum performance, direct addressing should be used. Therefore, you can use another array, the index of which is the coordinate of the dimension, and the value is a link to the corresponding entry in the dictionary. However, you can do it easier (and save on memory) if you arrange the array of elements accordingly so that the index of the element is its coordinate.
Organizing an array that implements a list of facts does not present any particular problems due to its simple structure. The only remark would be that it is advisable to calculate all aggregation methods that may be needed and which can be calculated incrementally (for example, sum).
So, we have described a method for storing data in the form of a hypercube. It allows you to generate a set of points in a multidimensional space based on information located in the data warehouse. In order for a person to be able to work with this data, it must be presented in a form convenient for processing. In this case, a pivot table and graphs are used as the main types of data presentation. Moreover, both of these methods are actually projections of a hypercube. In order to ensure maximum efficiency when constructing representations, we will start from what these projections represent. Let's start with the pivot table, as the most important one for data analysis.
Let's find ways to implement such a structure. There are three parts that make up a pivot table: row headers, column headers, and the actual table of aggregated fact values. The simplest way to represent a fact table is to use a two-dimensional array, the dimension of which can be determined by constructing the headers. Unfortunately, the simplest method will be the most inefficient, because the table will be very sparse, and memory will be used extremely inefficiently, as a result of which it will be possible to build only very small cubes, since otherwise there may not be enough memory. Thus, we need to select a data structure for storing information that will ensure the maximum speed of searching/adding a new element and at the same time the minimum consumption of RAM. This structure will be the so-called sparse matrices, about which you can read in more detail from Knuth. There are various ways to organize the matrix. In order to choose the option that suits us, we will first consider the structure of the table headers.
Headings have a clear hierarchical structure, so it would be natural to assume using a tree to store them. In this case, the structure of a tree node can be schematically depicted as follows:
Appendix C
In this case, it is logical to store a link to the corresponding element of the dimension table of a multidimensional cube as a dimension value. This will reduce memory costs for storing the slice and speed up work. Links are also used as parent and child nodes.
To add an element to a tree, you must have information about its location in the hypercube. As such information, you need to use its coordinate, which is stored in the dictionary of measurement values. Let's look at the scheme for adding an element to the header tree of a pivot table. In this case, we use the values of measurement coordinates as initial information. The order in which these dimensions are listed is determined by the desired aggregation method and matches the hierarchy levels of the header tree. As a result of the work, you need to obtain a list of columns or rows of the pivot table to which you need to add an element.
ApplicationD
We use measurement coordinates as the initial data to determine this structure. In addition, for definiteness, we will assume that we are defining the column of interest to us in the matrix (we will consider how to define a row a little later, since it is more convenient to use other data structures there; the reason for this choice is also see below). As coordinates, we take integers - numbers of measurement values that can be determined as described above.
So, after performing this procedure, we will obtain an array of references to the columns of the sparse matrix. Now you need to perform all the necessary actions with the strings. To do this, you need to find the required element inside each column and add the corresponding value there. For each dimension in the collection, you need to know the number of unique values and the actual set of these values.
Now let's look at the form in which the values inside the columns need to be represented - that is, how to determine the required row. There are several approaches you can use to achieve this. The simplest would be to represent each column as a vector, but since it will be very sparse, memory will be used extremely inefficiently. To avoid this, we will use data structures that will provide greater efficiency in representing sparse one-dimensional arrays (vectors). The simplest of them would be a regular list, singly or doubly linked, but it is uneconomical from the point of view of accessing elements. Therefore, we will use a tree, which will provide faster access to elements.
For example, you could use exactly the same tree as for columns, but then you would have to create your own tree for each column, which would lead to significant memory overhead and processing time. Let's do it a little more cunningly - we'll create one tree to store all combinations of dimensions used in strings, which will be identical to the one described above, but its elements will not be pointers to strings (which do not exist as such), but their indices, and the values of the indices themselves are not of interest to us and are used only as unique keys. We will then use these keys to find the desired element within the column. The columns themselves are most easily represented as a regular binary tree. Graphically, the resulting structure can be represented as follows:
Diagram 9. Image of a pivot table as a binary tree
You can use the same procedure as the procedure described above for determining the pivot table columns to determine the appropriate row numbers. In this case, row numbers are unique within one pivot table and identify elements in vectors that are columns of the pivot table. The simplest option for generating these numbers would be to maintain a counter and increment it by one when adding a new element to the row header tree. These column vectors themselves are most easily stored as binary trees, where the row number value is used as the key. In addition, it is also possible to use hash tables. Since the procedures for working with these trees are discussed in detail in other sources, we will not dwell on this and will consider the general scheme for adding an element to a column.
In general, the sequence of actions for adding an element to the matrix can be described as follows:
1. Determine the line numbers to which elements are added
2.Define a set of columns to which elements are added
3. For all columns, find the elements with the required row numbers and add the current element to them (adding includes connecting the required number of fact values and calculating aggregated values, which can be determined incrementally).
After executing this algorithm, we will obtain a matrix, which is a summary table that we needed to build.
Now a few words about filtering when constructing a slice. The easiest way to do this is at the stage of constructing the matrix, since at this stage there is access to all the required fields, and, in addition, aggregation of values is carried out. In this case, when retrieving an entry from the cache, its compliance with the filtering conditions is checked, and if it is not met, the entry is discarded.
Since the structure described above completely describes the pivot table, the task of visualizing it will be trivial. In this case, you can use standard table components that are available in almost all programming tools for Windows.
The first product to perform OLAP queries was Express (IRI). However, the term OLAP itself was coined by Edgar Codd, “the father of relational databases.” And Codd's work was funded by Arbor, a company that had released its own OLAP product, Essbase (later acquired by Hyperion, which was acquired by Oracle in 2007) the year before. Other well-known OLAP products include Microsoft Analysis Services (formerly called OLAP Services, part of SQL Server), Oracle OLAP Option, IBM's DB2 OLAP Server (essentially EssBase with additions from IBM), SAP BW, Brio products, BusinessObjects, Cognos, MicroStrategy and other manufacturers.
From a technical point of view, the products on the market are divided into “physical OLAP” and “virtual”. In the first case, there is a program that performs a preliminary calculation of aggregates, which are then stored in a special multidimensional database that provides quick retrieval. Examples of such products are Microsoft Analysis Services, Oracle OLAP Option, Oracle/Hyperion EssBase, Cognos PowerPlay. In the second case, the data is stored in relational DBMSs, and aggregates may not exist at all or may be created upon the first request in the DBMS or analytical software cache. Examples of such products are SAP BW, BusinessObjects, Microstrategy. Systems based on “physical OLAP” provide consistently better response times to queries than “virtual OLAP” systems. Virtual OLAP vendors claim greater scalability of their products to support very large volumes of data.
In this work, I would like to take a closer look at the BaseGroup Labs product - Deductor.
Deductor is an analytics platform, i.e. basis for creating complete application solutions. The technologies implemented in Deductor allow you to go through all the stages of building an analytical system on the basis of a single architecture: from creating a data warehouse to automatically selecting models and visualizing the results obtained.
System composition:
Deductor Studio is the analytical core of the Deductor platform. Deductor Studio includes a full set of mechanisms that allows you to obtain information from an arbitrary data source, carry out the entire processing cycle (cleaning, transforming data, building models), display the results in the most convenient way (OLAP, tables, charts, decision trees...) and export results.
Deductor Viewer is the end user workstation. The program allows you to minimize the requirements for personnel, because all required operations are performed automatically using previously prepared processing scripts; there is no need to think about the method of obtaining data and the mechanisms for processing it. The Dedustor Viewer user only needs to select the report of interest.
Deductor Warehouse is a multidimensional cross-platform data warehouse that accumulates all the information necessary for analyzing the subject area. The use of a single repository allows for convenient access, high processing speed, consistency of information, centralized storage and automatic support for the entire data analysis process.
4. Client-Server
Deductor Server is designed for remote analytical processing. It provides the ability to both automatically “run” data through existing scripts on the server and retrain existing models. Using Deductor Server allows you to implement a full-fledged three-tier architecture in which it serves as an application server. Access to the server is provided using Deductor Client.
Work principles:
1. Import data
Analysis of any information in Deductor begins with data import. As a result of import, the data is brought into a form suitable for subsequent analysis using all the mechanisms available in the program. The nature of the data, format, DBMS, etc. do not matter, because the mechanisms for working with everyone are unified.
2. Export data
The presence of export mechanisms allows you to send the results obtained to third-party applications, for example, transfer a sales forecast to the system to generate a purchase order or post the prepared report on a corporate website.
3. Data processing
Processing in Deductor means any action associated with some kind of data transformation, for example, filtering, model building, cleaning, etc. Actually, in this block the most important actions from the point of view of analysis are performed. The most significant feature of the processing mechanisms implemented in Deductor is that the data obtained as a result of processing can be processed again by any of the methods available to the system. Thus, you can build arbitrarily complex processing scenarios.
4. Visualization
You can visualize data in Deductor Studio (Viewer) at any stage of processing. The system independently determines how it can do this, for example, if a neural network is trained, then in addition to tables and diagrams, you can view the neural network graph. The user needs to select the desired option from the list and configure several parameters.
5. Integration mechanisms
Deductor does not provide data entry tools - the platform is focused solely on analytical processing. To use information stored in heterogeneous systems, flexible import-export mechanisms are provided. Interaction can be organized using batch execution, working in OLE server mode and accessing the Deductor Server.
6.Replication of knowledge
Deductor allows you to implement one of the most important functions of any analytical system - support for the process of knowledge replication, i.e. providing the opportunity for employees who do not understand analysis methods and methods of obtaining a particular result to receive an answer based on models prepared by an expert.
Zconclusion
This paper examined such an area of modern information technologies as data analysis systems. The main tool for analytical information processing - OLAP - technology is analyzed. The essence of the concept of OLAP and the importance of OLAP systems in a modern business process are revealed in detail. The structure and process of operation of a ROLAP server is described in detail. As an example of the implementation of OLAP data technologies, the Deductor analytical platform is given. The submitted documentation has been developed and meets the requirements.
OLAP technologies are a powerful tool for real-time data processing. An OLAP server allows you to organize and present data across various analytical areas and turns data into valuable information that helps companies make more informed decisions.
The use of OLAP systems provides consistently high levels of performance and scalability, supporting multi-gigabyte data volumes that can be accessed by thousands of users. With the help of OLAP technologies, access to information is carried out in real time, i.e. Query processing no longer slows down the analysis process, ensuring its speed and efficiency. Visual administration tools allow you to develop and implement even the most complex analytical applications, making the process simple and fast.
Similar documents
The basis of the concept of OLAP (On-Line Analytical Processing) is operational analytical processing of data, features of its use on the client and on the server. General characteristics of the basic requirements for OLAP systems, as well as methods of storing data in them.
abstract, added 10/12/2010
OLAP: general characteristics, purpose, goals, objectives. Classification of OLAP products. Principles of building an OLAP system, library of CubeBase components. Dependence of the performance of client and server OLAP tools on the increase in data volume.
course work, added 12/25/2013
Eternal data storage. The essence and significance of the OLAP (On-line Analytical Processing) tool. Databases and data warehouses, their characteristics. Structure, data storage architecture, their suppliers. Some tips for improving the performance of OLAP cubes.
test, added 10/23/2010
Construction of data analysis systems. Building algorithms for designing an OLAP cube and creating queries for the constructed pivot table. OLAP technology for multidimensional data analysis. Providing users with information for making management decisions.
course work, added 09/19/2008
Basic information about OLAP. Operational analytical data processing. Classification of OLAP products. Requirements for online analytical processing tools. The use of multidimensional databases in operational analytical processing systems, their advantages.
course work, added 06/10/2011
Development of website analysis subsystems using Microsoft Access and Olap technologies. Theoretical aspects of developing a data analysis subsystem in the information system of a music portal. Olap technologies in the research object analysis subsystem.
course work, added 11/06/2009
Consideration of OLAP tools: classification of storefronts and information warehouses, the concept of a data cube. Architecture of a decision support system. Software implementation of the "Abitura" system. Creating a Web report using Reporting Services technologies.
course work, added 12/05/2012
Data storage, principles of organization. Processes for working with data. OLAP structure, technical aspects of multidimensional data storage. Integration Services, populating data warehouses and data marts. Capabilities of systems using Microsoft technologies.
course work, added 12/05/2012
Construction of a data warehouse diagram for a trading enterprise. Descriptions of storage relationship diagrams. Displaying product information. Creation of an OLAP cube for further analysis of information. Development of queries to evaluate the efficiency of a supermarket.
test, added 12/19/2015
Purpose of data storage. SAP BW architecture. Building analytical reporting based on OLAP cubes in the SAP BW system. Key differences between a data warehouse and an OLTP system. Overview of BEx functional areas. Creating a query in BEx Query Designer.
The OLAP mechanism is one of the popular methods of data analysis today. There are two main approaches to solving this problem. The first of them is called Multidimensional OLAP (MOLAP) - implementation of the mechanism using a multidimensional database on the server side, and the second Relational OLAP (ROLAP) - construction of cubes on the fly based on SQL queries to a relational DBMS. Each of these approaches has its pros and cons. Their comparative analysis is beyond the scope of this article. We will describe our implementation of the core of the desktop ROLAP module.
This task arose after using a ROLAP system built on the basis of Decision Cube components included in Borland Delphi. Unfortunately, the use of this set of components showed poor performance on large amounts of data. This problem can be mitigated by trying to cut out as much data as possible before feeding it into cubes. But this is not always enough.
You can find a lot of information about OLAP systems on the Internet and in the press, but almost nowhere is it said about how it works inside. Therefore, the solution to most problems was given to us by trial and error.
Scheme of work
The general scheme of operation of a desktop OLAP system can be represented as follows:
The operating algorithm is as follows:
- Receiving data in the form of a flat table or the result of executing an SQL query.
- Caching data and converting it to a multidimensional cube.
- Displaying the constructed cube using a crosstab or chart, etc. In general, an arbitrary number of views can be connected to one cube.
Let's consider how such a system can be arranged internally. We will start from the side that can be seen and touched, that is, from the displays.
The displays used in OLAP systems most often come in two types: cross-tabs and charts. Let's look at a crosstab, which is the basic and most common way to display a cube.
Cross table
In the figure below, rows and columns containing aggregated results are shown in yellow, cells containing facts are in light gray, and cells containing dimensional data are in dark gray.

Thus, the table can be divided into the following elements, which we will work with in the future:

When filling out the matrix with facts, we must proceed as follows:
- Based on the measurement data, determine the coordinates of the element to be added in the matrix.
- Determine the coordinates of the columns and rows of the totals that are affected by the added element.
- Add an element to the matrix and the corresponding total columns and rows.
It should be noted that the resulting matrix will be very sparse, which is why its organization in the form of a two-dimensional array (the option lying on the surface) is not only irrational, but, most likely, impossible due to the large dimension of this matrix, for storing which there is no No amount of RAM is enough. For example, if our cube contains information about sales for one year, and if it has only 3 dimensions - Customers (250), Products (500) and Date (365), then we will get a fact matrix of the following dimensions:
Number of elements = 250 x 500 x 365 = 45,625,000
And this despite the fact that there may be only a few thousand filled elements in the matrix. Moreover, the greater the number of dimensions, the more sparse the matrix will be.
Therefore, to work with this matrix, you need to use special mechanisms for working with sparse matrices. Various options for organizing a sparse matrix are possible. They are quite well described in the programming literature, for example, in the first volume of the classic book "The Art of Programming" by Donald Knuth.
Let us now consider how we can determine the coordinates of a fact, knowing the dimensions corresponding to it. To do this, let's take a closer look at the header structure:
In this case, you can easily find a way to determine the numbers of the corresponding cell and the totals in which it falls. Several approaches can be proposed here. One of them is to use a tree to find matching cells. This tree can be constructed by traversing the selection. In addition, an analytical recurrence formula can be easily defined to calculate the required coordinate.
Data preparation
The data stored in the table needs to be transformed in order to be used. Thus, in order to improve performance when building a hypercube, it is desirable to find unique elements stored in columns that are dimensions of the cube. In addition, you can perform preliminary aggregation of facts for records that have the same dimension values. As mentioned above, the unique values available in the measurement fields are important to us. Then the following structure can be proposed for storing them:

By using this structure, we significantly reduce the memory requirement. Which is quite relevant, because... To increase operating speed, it is advisable to store data in RAM. In addition, you can only store an array of elements, and dump their values to disk, since we will only need them when displaying the cross-tab.
CubeBase Component Library
The ideas described above were the basis for creating the CubeBase component library.

TCubeSource carries out caching and conversion of data into an internal format, as well as preliminary aggregation of data. Component TCubeEngine carries out calculations of the hypercube and operations with it. In fact, it is an OLAP engine that transforms a flat table into a multidimensional data set. Component TCubeGrid displays the cross-tab and controls the display of the hypercube. TCubeChart allows you to see the hypercube in the form of graphs, and the component TCubePivote controls the operation of the cube core.
Performance Comparison
This set of components showed much higher performance than Decision Cube. So, on a set of 45 thousand records, the Decision Cube components required 8 minutes. to build a pivot table. CubeBase loaded data in 7 seconds. and building a pivot table in 4 seconds. When testing on 700 thousand Decision Cube records, we did not receive a response within 30 minutes, after which we canceled the task. CubeBase loaded data in 45 seconds. and building a cube in 15 seconds.
On data volumes of thousands of records, CubeBase processed tens of times faster than Decision Cube. On tables with hundreds of thousands of records - hundreds of times faster. And high performance is one of the most important indicators of OLAP systems.
OLAP(from the English OnLine Analytical Processing - operational analytical data processing, also: real-time analytical data processing, interactive analytical data processing) - an approach to analytical data processing based on their multidimensional hierarchical representation, which is part of the broader field of information technology - business analytics ().
For a catalog of OLAP solutions and projects, see the section OLAP on TAdviser.
From the user's point of view, OLAP-systems provide tools for flexible viewing of information in various sections, automatic receipt of aggregated data, performing analytical operations of convolution, detailing, and comparison over time. All this makes OLAP systems a solution with obvious advantages in the field of data preparation for all types of business reporting, involving the presentation of data in various sections and different levels of hierarchy - for example, sales reports, various forms of budgets, and so on. The advantages of such a representation in other forms of data analysis, including forecasting, are obvious.
Requirements for OLAP systems. FASMI
The key requirement for OLAP systems is speed, which allows them to be used in the process of an analyst’s interactive work with information. In this sense, OLAP systems are contrasted, firstly, with traditional RDBMS, samples from which with typical queries for analysts using grouping and aggregation of data are usually expensive in terms of waiting time and loading RDBMS, so interactive work with them with any significant amount of data is difficult. Secondly, OLAP systems are also opposed to the usual flat-file presentation of data, for example, in the form of frequently used traditional spreadsheets, the presentation of multidimensional data in which is complex and not intuitive, and operations for changing the slice - points of view on the data - also require time and complicate interactive work with data.
At the same time, on the one hand, data requirements specific to OLAP systems usually imply storing data in special structures optimized for typical OLAP tasks; on the other hand, directly extracting data from existing systems during the analysis process would lead to a significant drop in their performance.
Therefore, an important requirement is to provide the most flexible import-export link between existing systems acting as a data source and an OLAP system, as well as an OLAP system and external data analysis and reporting applications.
Moreover, such a combination must satisfy the obvious requirements of supporting import-export from several data sources, implementing procedures for cleaning and transforming data, unifying the used classifiers and reference books. In addition, these requirements are supplemented by the need to take into account various data update cycles in existing information systems and unify the required level of data detail. The complexity and versatility of this problem led to the emergence of the concept data warehouses, and, in a narrow sense, to the identification of a separate class of data conversion and conversion utilities - ETL (Extract Transform Load).
Active Data Storage Models
We indicated above that OLAP assumes a multidimensional hierarchical representation of data, and, in a sense, is opposed to those based on RDBMS systems.
This, however, does not mean that all OLAP systems use a multidimensional model to store active, “working” system data. Since the active data storage model influences all requirements dictated by the FASMI test, its importance is emphasized by the fact that it is on this basis that OLAP subtypes are traditionally distinguished - multidimensional (MOLAP), relational (ROLAP) and hybrid (HOLAP).
However, some experts, led by the aforementioned Nigel Pends , indicate that classification based on one criterion is not complete enough. Moreover, the vast majority of existing OLAP systems will be of the hybrid type. Therefore, we will dwell in more detail on active data storage models, mentioning which of them correspond to which of the traditional OLAP subtypes.
Storing active data in a multidimensional database
In this case, OLAP data is stored in multidimensional DBMS, using designs optimized for this type of data. Typically, multidimensional DBMSs support all typical OLAP operations, including aggregation along the required hierarchy levels and so on.
This type of data storage, in a sense, can be called classic for OLAP. However, all steps for preliminary data preparation are fully necessary for it. Typically, multidimensional DBMS data is stored on disk, however, in some cases, to speed up data processing, such systems allow data to be stored in random access memory. For the same purposes, storing pre-calculated aggregate values and other calculated values in the database is sometimes used.
Multidimensional DBMS, fully supporting multi-user access with competing read and write transactions are quite rare; the usual mode for such DBMSs is single-user with write access with multi-user read access, or multi-user read-only.
Among the shortcomings characteristic of some implementations of multidimensional DBMSs and OLAP systems based on them, one can note their susceptibility to an unpredictable growth in the amount of space occupied by the database from a user point of view. This effect is caused by the desire to minimize the reaction time of the system, which dictates storing pre-calculated values of aggregate indicators and other quantities in the database, which causes a nonlinear increase in the volume of information stored in the database with the addition of new data values or measurements.
The extent to which this problem manifests itself, as well as the related problems of efficiently storing sparse data cubes, is determined by the quality of the approaches and algorithms used for specific implementations of OLAP systems.
Storing active data in a relational database
OLAP data can also be stored in traditional RDBMS. In most cases, this approach is used when trying to “painlessly” integrate OLAP with existing accounting systems, either based on RDBMS data warehouses. At the same time, this approach requires some additional capabilities from the RDBMS to ensure effective fulfillment of the requirements of the FASMI test (in particular, ensuring minimal system response time). Typically OLAP data is stored in denormalized form, and some of the pre-calculated aggregates and values are stored in special tables. When stored in a normalized form, the effectiveness of RDBMS as a method for storing active data decreases.
The problem of choosing effective approaches and algorithms for storing precomputed data is also relevant for OLAP systems based on RDBMS, so manufacturers of such systems usually focus on the merits of the approaches used.
In general, it is believed that OLAP systems based on RDBMS are slower than systems based on multidimensional DBMSs, including due to data storage structures that are less efficient for OLAP tasks, but in practice this depends on the characteristics of a particular system.
Among the advantages of storing data in an RDBMS is the greater scalability of such systems.
Storing active data in flat files
This approach involves storing chunks of data in regular files. It is usually used as an addition to one of the two main approaches in order to speed up work by caching current data on disk or in the RAM of the client PC.
Hybrid approach to data storage
Most manufacturers of OLAP systems that promote their comprehensive solutions, often including, in addition to the OLAP system itself, DBMS, tools ETL (Extract Transform Load) and reporting, currently use a hybrid approach to organizing the storage of active system data, distributing it in one way or another between an RDBMS and specialized storage, as well as between disk structures and caching in RAM.
Since the effectiveness of such a solution depends on the specific approaches and algorithms used by the manufacturer to determine whether what data and where to store, then hastily draw conclusions about the initially greater efficiency of such solutions as a class without assessing the specific features of the system under consideration.
OLAP(eng. on-line analytical processing) – a set of methods for dynamic processing of multidimensional queries in analytical databases. Such data sources are usually quite large in volume, and one of the most important requirements in the tools used to process them is high speed. In relational databases, information is stored in separate tables that are well normalized. But complex multi-table queries are executed quite slowly in them. Significantly better performance in terms of processing speed in OLAP systems is achieved due to the peculiarities of the data storage structure. All information is clearly organized, and two types of data storage are used: measurements(contain directories divided into categories, for example, points of sale, clients, employees, services, etc.) and data(characterize the interaction of elements of various dimensions, for example, on March 3, 2010, seller A provided a service to client B in store C for the amount of D monetary units). Measures are used to calculate results in the Analysis Cube. Measures are collections of facts aggregated by corresponding selected dimensions and their elements. Thanks to these features, complex queries with multidimensional data take much less time than with relational sources.
One of the main vendors of OLAP systems is the corporation Microsoft. Let's consider the implementation of the principles OLAP on practical examples of creating an analytical cube in applications Microsoft SQL Server Business Intelligence Development Studio(BIDS) and Microsoft Office PerformancePoint Server Planning Business Modeler(PPS) and get acquainted with the possibilities of visual representation of multidimensional data in the form of graphs, charts and tables.
For example, in BIDS it is necessary to create an OLAP cube using data about an insurance company, its employees, partners (clients) and points of sale. Let's assume that the company provides one type of service, so measurement of services will not be needed.
First let's define the measurements. The following entities (data categories) are associated with the company’s activities:
- Points of sale
- Employees
- Partners
Next, you need one table to store facts (fact table).
Information can be entered into tables manually, but the most common way is to load data using the Import Wizard from various sources.
The following figure shows the flow of manually creating and populating dimension and fact tables:
Fig.1. Tables of dimensions and facts in the analytical database. Creation sequence
After creating a multidimensional data source in BIDS, you can view its presentation (Data Source View). In our example, we will get the circuit shown in the figure below.
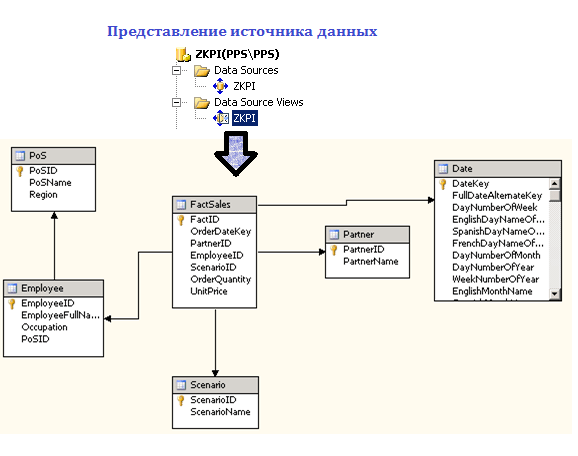
Fig.2. Data Source View in Business Intelligence Development Studio (BIDS)
As you can see, the fact table is connected to the dimension tables through a one-to-one correspondence of identifier fields (PartnerID, EmployeeID, etc.).
Let's look at the result. On the cube explorer tab, by dragging measures and dimensions into the totals, rows, columns and filters fields, we can get a view of the data of interest (for example, concluded transactions on insurance contracts concluded by a certain employee in 2005).
The concept of multidimensional data analysis is closely associated with operational analysis, which is performed using OLAP systems.
OLAP (On-Line Analytical Processing) is a technology for operational analytical data processing that uses methods and tools for collecting, storing and analyzing multidimensional data to support decision-making processes.
The main purpose of OLAP systems is to support analytical activities and arbitrary (the term ad-hoc is often used) requests from user analysts. The purpose of OLAP analysis is to test emerging hypotheses.
The origins of OLAP technology are the founder of the relational approach, E. Codd. In 1993, he published an article entitled "OLAP for User Analysts: What It Should Be." This paper outlines the basic concepts of online analytics and identifies the following 12 requirements that must be met by products that enable online analytics. Tokmakov G.P. Database. Database concept, relational data model, SQL languages. P. 51
Listed below are the 12 rules outlined by Codd that define OLAP.
1. Multidimensionality -- an OLAP system at the conceptual level should present data in the form of a multidimensional model, which simplifies the processes of analysis and perception of information.
2. Transparency -- the OLAP system must hide from the user the real implementation of the multidimensional model, the method of organization, sources, processing and storage means.
3. Availability -- An OLAP system must provide the user with a single, consistent and holistic data model, providing access to data regardless of how or where it is stored.
4. Consistent performance when developing reports - the performance of OLAP systems should not decrease significantly as the number of dimensions on which analysis is performed increases.
5. Client-server architecture -- the OLAP system must be able to work in a client-server environment, because Most of the data that today needs to be subjected to operational analytical processing is stored distributedly. The main idea here is that the server component of the OLAP tool should be sufficiently intelligent and allow the construction of a common conceptual scheme based on the generalization and consolidation of various logical and physical schemes of corporate databases to provide the effect of transparency.
6. Dimensional equality -- The OLAP system must support a multidimensional model in which all dimensions are equal. If necessary, additional characteristics can be provided to individual dimensions, but this capability must be provided to any dimension.
7. Dynamic management of sparse matrices -- the OLAP system must provide optimal processing of sparse matrices. The access speed must be maintained regardless of the location of the data cells and be constant for models with different numbers of dimensions and varying degrees of data sparsity.
8. Support for multi-user mode - the OLAP system must provide the ability for several users to work together with one analytical model or create different models for them from single data. In this case, both reading and writing data is possible, so the system must ensure its integrity and security.
9. Unlimited cross operations -- the OLAP system must ensure that the functional relationships described using a certain formal language between the cells of the hypercube are preserved when performing any slice, rotation, consolidation or drill-down operations. The system should independently (automatically) perform the transformation of established relationships, without requiring the user to redefine them.
10. Intuitive data manipulation -- An OLAP system must provide a way to perform slicing, rotating, consolidating, and drilling operations on a hypercube without the user having to do a lot of interface manipulation. The dimensions defined in the analytical model must contain all the necessary information to perform the above operations.
11. Flexible options for obtaining reports -- the OLAP system must support various methods of data visualization, i.e. reports should be presented in any possible orientation. Reporting tools must present synthesized data or information resulting from the data model in any possible orientation. This means that rows, columns or pages must show from 0 to N dimensions at a time, where N is the number of dimensions of the entire analytical model. Additionally, each content dimension shown in a single post, column, or page must allow any subset of the elements (values) contained in the dimension to be shown in any order.
12. Unlimited dimension and number of aggregation levels - research on the possible number of necessary dimensions required in the analytical model showed that up to 19 dimensions can be used simultaneously. Hence, it is strongly recommended that the analytical tool be able to provide at least 15, and preferably 20, measurements simultaneously. Moreover, each of the common dimensions should not be limited in the number of user-analyst-defined aggregation levels and consolidation paths.
Codd's Additional Rules.
The set of these requirements, which served as the de facto definition of OLAP, quite often causes various complaints, for example, rules 1, 2, 3, 6 are requirements, and rules 10, 11 are unformalized wishes. Tokmakov G.P. Database. Database concept, relational data model, SQL languages. P. 68 Thus, Codd's listed 12 requirements do not allow us to accurately define OLAP. In 1995, Codd added the following six rules to the above list:
13. Batch Retrieval vs. Interpretation -- An OLAP system must provide access to both its own and external data equally effectively.
14. Support for all OLAP analysis models -- An OLAP system must support all four data analysis models defined by Codd: categorical, interpretive, speculative and stereotypical.
15. Processing of non-normalized data -- the OLAP system must be integrated with non-normalized data sources. Data modifications made in the OLAP environment should not result in changes to data stored in the original external systems.
16. Saving OLAP results: storing them separately from the source data - an OLAP system operating in read-write mode must save the results separately after modifying the source data. In other words, the security of the original data is ensured.
17. Elimination of missing values - An OLAP system, when presenting data to the user, must discard all missing values. In other words, missing values must be different from null values.
18. Handling Missing Values -- The OLAP system must ignore all missing values without regard to their source. This feature is related to the 17th rule.
In addition, Codd divided all 18 rules into the following four groups, calling them features. These groups were named B, S, R and D.
The main features of (B) include the following rules:
Multidimensional conceptual representation of data (rule 1);
Intuitive data manipulation (rule 10);
Availability (rule 3);
Batch extraction vs. interpretation (rule 13);
Support for all OLAP analysis models (rule 14);
Client-server architecture (rule 5);
Transparency (rule 2);
Multi-user support (rule 8)
Special Features (S):
Processing of non-normalized data (rule 15);
Storing OLAP results: storing them separately from the source data (rule 16);
Elimination of missing values (rule 17);
Handling missing values (rule 18). Reporting Features (R):
Flexibility of reporting (rule 11);
Standard reporting performance (rule 4);
Automatic physical layer configuration (modified original rule 7).
Dimension Control (D):
Universality of measurements (rule 6);
Unlimited number of dimensions and aggregation levels (rule 12);
Unlimited operations between dimensions (rule 9).